|
 |
Lezione n. 02Dalla macchina di Turing al computerdi Gino Roncaglia
Argomenti trattati nella lezione 02:
Premessa
In linea generale, un computer è uno strumento per elaborare informazione. Il computer lavora dunque partendo da informazione in ingresso (l'input del processo di elaborazione), la elabora in base a una serie di regole (un programma), e restituisce informazione in uscita (l'output del processo). Come si è già accennato, la grandissima maggioranza dei computer oggi utilizzati è digitale, lavora cioè con informazione in formato digitale. Avendo bisogno di informazioni da 'masticare', il computer deve possedere dei dispositivi di input, attraverso i quali inserire i dati su cui lavorare; dato che di norma desideriamo vedere (o comunque utilizzare) i risultati del processo di elaborazione, deve possedere anche dei dispositivi di output, attraverso i quali restituirci i risultati del lavoro svolto. Inoltre, avrà bisogno di un programma in base al quale operare.
Dispositivi di input-output e CPU (unità di elaborazione centrale)Fin qui, siamo stati forse un po' astratti; proviamo allora, per prima cosa, a capire concretamente cosa sono i dispositivi di input e di output. Un tipico dispositivo di input è la tastiera: alla pressione dei tasti corrisponde l'invio verso l'unità di elaborazione dei caratteri corrispondenti (o meglio, della codifica digitale dei caratteri corrispondenti: ricordate le nostre tavole di codifica dei caratteri?). Anche il mouse è un dispositivo di input: attraverso appositi sensori, il computer riceve informazioni (naturalmente, in formato digitale!) sullo spostamento della pallina collocata alla base del mouse stesso, e le interpreta come spostamenti da far eseguire al cursore sullo schermo; analogamente, il 'click' del mouse (la pressione di uno dei suoi tasti) viene ricevuto e interpretato in accordo con le istruzioni fornite dal programma che si sta utilizzando.
Altri dispositivi di input sono ad esempio uno scanner (attraverso di esso, come si è visto, il computer 'riceve' immagini tradotte in formato digitale) o una scheda di acquisizione sonora. Quanto ai dispositivi di output, vengono subito in mente la stampante e lo schermo; uno schermo sensibile al tatto, o touch screen, come quelli disponibili nelle biglietterie ferroviarie, è naturalmente sia un dispositivo di input sia un dispositivo di output.
Vi è poi una classe di dispositivi un po' particolare, quella rappresentata dagli strumenti che permettono al computer di leggere (e dunque ricevere) e di scrivere (e dunque inviare) dati - le nostre lunghe catene di '0' e '1' - da e verso un supporto in grado di conservarli anche quando il computer è spento. Si tratta delle cosiddette memorie di massa, come i floppy disk e i dischi rigidi: ne parleremo in maniera più approfondita in seguito. Spesso le memorie di massa non vengono considerate dispositivi di input e output, perché i dati che vi vengono conservati sono comunque in formato digitale: in un certo senso, sono dati che il computer conserva nel suo linguaggio, dunque questi dispositivi di memorizzazione non servono direttamente a noi per comunicare - nel nostro linguaggio - con il computer. D'altro canto, è indubbio che i dispositivi di memoria di massa vengano usati dal computer per ricevere informazione in entrata, e inviare informazione in uscita: da questo punto di vista, anch'essi potrebbero essere visti come dispositivi di input e output. Un computer può in realtà disporre di molti tipi diversi di memorie, alcune delle quali, anziché immagazzinare in forma relativamente stabile informazioni per usi futuri, vengono direttamente utilizzate durante il processo di elaborazione, ad esempio per conservare i risultati parziali di un calcolo, o le istruzioni del programma che il computer sta eseguendo. In questi casi, pensare a dispositivi 'esterni' (periferiche) di input/output sarebbe effettivamente fuorviante: possiamo pensare piuttosto a vere e proprie componenti interne, indispensabili allo svolgimento del processo di elaborazione dei dati. Ma di tutto questo ci occuperemo tra breve. Prima, però, torniamo al nostro modello generale (e in verità ancora piuttosto generico) di computer: dispositivi di input, dispositivi di output, e, da qualche parte 'in mezzo' fra i dispositivi di input e di output, il 'cervello' vero e proprio del computer, quello che - seguendo un programma - elabora l'informazione. Questo modello è abbastanza intuitivo. Ma, a ben guardare, non ci dice molto: cosa sia, e come funzioni, quella che in termini un po' più accurati possiamo cominciare a chiamare l'unità di elaborazione centrale del computer (CPU - Central Processing Unit), rimane del tutto in ombra. Potremmo essere tentati di lasciare agli informatici il compito di occuparsi della CPU; dal canto nostro, la considereremmo come una sorta di 'scatola nera': non sappiamo bene come funzioni, l'importante per noi è che funzioni. Questo atteggiamento è del tutto legittimo, e in una certa misura l'architettura interna di un computer è in effetti una scatola nera per la stragrande maggioranza dei suoi utenti, ivi compresi quelli più avanzati. Ma, fermo restando che non potremo certo pretendere di trasformare in pochi minuti il lettore in un informatico di professione, non sarebbe forse un peccato rinunciare ad avere un'idea - almeno in termini molto generali - di come veramente funzioni un computer?
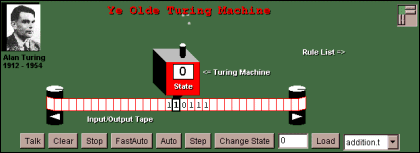
La macchina di TuringPer farlo, e prima di tornare a prendere in considerazione più da vicino la struttura concettuale di un computer, può essere utile presentare una semplice macchina astratta capace di elaborare informazione in formato digitale sulla base di un programma composto da regole: la cosiddetta macchina di Turing. La macchina di Turing prende il nome dal logico e matematico inglese Alan Turing (vedi scheda biografica), ed è solo una costruzione concettuale. Ma si tratta di una costruzione concettuale di grande fascino: semplicissima (come vedremo, gli 'ingredienti di base' di una macchina di Turing sono pochi e di facile comprensione) ed estremamente potente. Immaginiamo dunque di avere a disposizione un nastro di lunghezza potenzialmente infinita (non protestate - la nostra promessa era che la macchina di Turing fosse concettualmente semplice, non che fosse anche facile da realizzare fisicamente!), diviso in singole celle in ciascuna delle quali può essere scritto un simbolo. L'alfabeto dei simboli che possono essere scritti nelle caselle del nastro sarà finito; per semplificare, visto che abbiamo imparato nella prima lezione che è sempre possibile 'tradurre' in formato binario alfabeti finiti più complessi (come le dieci cifre della notazione decimale o le lettere che usiamo per scrivere), assumiamo che su ogni casella del nastro si possano scrivere solo i simboli '0' o '1'. Oltre al nastro con le sue cellette, la nostra macchina di Turing comprenderà una testina di lettura/scrittura (pensiamo a qualcosa di simile alla testina di un registratore) che sia in grado di leggere il simbolo che si trova nella celletta sopra la quale è posizionata, e di scrivere su tale celletta in modo da potere - volendo - modificare il simbolo che ha letto. La testina dovrà essere in grado di scorrere sul nastro in entrambe le direzioni - o, a piacere, il nastro dovrà essere in grado di scorrere in entrambe le direzioni sotto la testina.
Infine, la macchina di Turing potrà assumere una serie finita di stati distinti. Attraverso la distinzione di questi stati, potremo specificare le istruzioni del programma da fare eseguire alla macchina. Ad esempio, potremmo stabilire che se la macchina si trova nello stato a e legge un 1 nella casella su cui è posizionata la testina, la testina si dovrà spostare a destra di una casella e la macchina dovrà passare nello stato b (a questo punto, dovremo ulteriormente specificare le istruzioni che la macchina deve eseguire quando si trova nello stato b, in dipendenza da quello che la testina legge sul nastro, e così via). Insomma: la macchina disporrà di un programma in grado di fare spostare la testina sul nastro e di far cambiare stato alla macchina stessa in dipendenza dallo stato in cui la macchina si trovava in precedenza e dal simbolo sul quale la testina si trova posizionata. La particolare successione di '0' e di '1' scritta sul nastro prima dell'avvio della macchina rappresenta l'input della macchina - i dati sui quali vogliamo farla lavorare. La particolare successione di '0' e di '1' scritta sul nastro nel momento in cui la macchina si ferma (se si ferma - come vedremo potrebbe anche non farlo) rappresenta invece l'output della macchina, il risultato del suo processo di elaborazione. Sembra complicato? Per capire meglio, date un'occhiata alla scheda
che spiega come descrivere una macchina di Turing in grado di fare
una somma. E poi, se vi va, fate un po' di esperimenti con il
programma di simulazione di una macchina
di Turing disponibile sul CD-ROM di questo corso e sul sito
Internet della Buena
Vista University Sembra incredibile, ma una macchina di Turing è in grado di effettuare moltissime operazioni anche molto complesse: in effetti, è in grado di effettuare tutte le operazioni che può compiere il più potente dei computer a noi noti, ovvero, per parlare in forma più tecnica, è in grado di calcolare il valore di qualsiasi funzione per la quale disponiamo di procedure effettive di computazione. Se il tema vi interessa, potete dare un'occhiata anche alla scheda che approfondisce alcuni temi teorici di grande importanza legati alla macchina di Turing. Anche se - nel caso che abbiamo descritto - la macchina di Turing lavora solamente con due simboli, non è affatto detto che si debba limitare a fare operazioni numeriche: come abbiamo visto nella prima lezione, è infatti possibile convertire in formato binario anche informazioni testuali, o grafiche, o sonore. Così, ad esempio, possiamo costruire una macchina di Turing che riceva come input una tavola delle calorie e il menù di un pasto (nel nostro esempio, il tutto sarà naturalmente codificato in forma binaria secondo i principi che abbiamo discusso nella prima lezione) e restituisca come output il totale delle calorie previste dal pasto, o una macchina di Turing che conti le occorrenze delle parole 'cuore' e 'amore' nelle canzoni di Claudio Baglioni (che dovranno evidentemente esserle date, anch'esse codificate, come input), o ancora - questo è abbastanza facile - una macchina di Turing che trasformi tutte le lettere maiuscole di un testo in minuscole e viceversa. Insomma: dobbiamo sempre ricordare che una computazione è un processo di manipolazione di simboli governato da regole: non è affatto detto che i simboli - a partire dall''1' e dallo '0' della codifica binaria - debbano rappresentare necessariamente numeri, e non è affatto detto che le regole utilizzate debbano essere sempre regole matematiche.
Dalla macchina di Turing alla CPUNella maggior parte dei casi, costruire davvero l'elenco di istruzioni da fornire alla macchina di Turing perché esegua il lavoro che le chiediamo può costituire un'impresa lunga e faticosa, tanto da diventare praticamente irrealizzabile. Ma il modello teorico costituito dalla macchina di Turing per certi versi non è troppo lontano - pur con le dovute differenze - dall'idea di computer sviluppata negli anni '40 da un altro pioniere dell'informatica, l'ungherese John von Neumann. Si tratta della cosiddetta macchina di von Neumann: anch'essa in primo luogo una costruzione teorica, che influenzò però direttamente la realizzazione di due fra i primi computer: l'ENIAC (Electronic Numerical Integrator and Computer) e l'EDVAC (Electronic Discrete Variable Automatic Computer).
Quali sono i punti di contatto fra la nostra macchina di Turing e un vero computer basato sul modello di von Neumann? Ebbene, anche il lavoro che avviene all'interno del processore di un computer è una incessante lettura e trasformazione di '0' e '1' (che codificano informazione), effettuata seguendo un insieme di regole. Al posto del nastro infinito, nel microprocessore troveremo una serie di registri, ovvero piccole serie di cellette composte di norma da elementi (corrispondenti alle singole cellette del nastro) che possono assumere due stati, e che sono per questo detti bistabili. I due stati possono corrispondere ad esempio a due diverse polarizzazioni elettriche, e rappresenteranno il nostro '0' e il nostro '1'. L'unità di elaborazione centrale (CPU) lavora per lo più trasferendo (copiando) informazioni in formato binario dalla memoria ai registri, leggendo il valore che trova nei registri, se necessario modificandolo in base alle regole previste dal programma che sta eseguendo, e quindi trasferendo nuovamente nella memoria il valore eventualmente modificato. Fra i registri dei quali dispone la CPU, ve ne saranno alcuni destinati a contenere i dati sui quali il processore sta lavorando, altri che conterranno - sempre in forma codificata - le istruzioni che il processore deve eseguire, mentre un registro 'contatore' si occuperà di controllare l'ordine con il quale vengono eseguite le istruzioni del programma, tenendo nota di quale istruzione il processore sta eseguendo in quel determinato momento. Molte istruzioni di programma richiedono l'intervento di una componente particolarmente importante della CPU, l'Unità Aritmetico-Logica o ALU: come dice il suo nome, la ALU compie le principali operazioni aritmetiche (abbiamo già visto un esempio del tipo di istruzioni che consentono di compiere queste operazioni nel caso della macchina di Turing, e come si è detto il lavoro svolto dalla CPU non è troppo diverso) e logiche. Operazioni 'logiche'? Un momento, direte voi: le operazioni aritmetiche sono un concetto familiare, ma le operazioni logiche sembrano invece qualcosa di piuttosto misterioso. Di cosa si tratta?
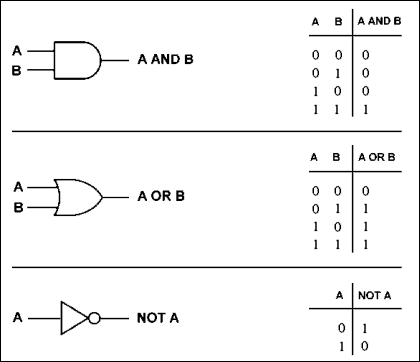
Operazioni logicheSemplice: possiamo pensare alle operazioni logiche (dette anche booleane: le principali sono AND, OR, NOT) come operazioni nelle quali i simboli '1' e '0' rappresentano rispettivamente 'vero' e 'falso'. Vediamo come funzionano. L'operazione booleana AND accetta come input due bit, e restituisce come output un solo bit: il bit di output avrà valore '1' ('vero') se e solo se entrambi i bit di input avevano valore '1' ('vero'), e avrà valore '0' ('falso') in tutti gli altri casi. Questa operazione si chiama AND perché corrisponde abbastanza da vicino alla congiunzione 'e'. Facciamo un esempio: la proposizione complessa "oggi piove, e oggi è mercoledì" sarà vera (avrà valore '1') se e solo se sono vere (hanno valore '1') entrambe le proposizioni semplici che la compongono ("oggi piove", "oggi è mercoledì"). Se oggi piove, ma è lunedì anziché mercoledì, la proposizione complessa sarà falsa, e lo stesso avverrà se oggi è effettivamente mercoledì, ma il cielo è terso e sereno. Possiamo pensare ai dati rappresentati dalla verità o falsità di ciascuna delle due proposizioni "oggi piove" e "oggi è mercoledì" come agli 'input' in base ai quali calcolare se è vera o falsa la proposizione composta "oggi piove, e oggi è mercoledì". Il nostro AND logico lavora proprio in questo modo: partendo dall'input costituito dai valori di verità di due proposizioni più semplici, e calcolando sulla loro base il valore di verità della corrispondente congiunzione; questo valore di verità viene quindi restituito come output. Anche l'operazione OR accetta come input due bit, e ne restituisce uno: in questo caso, però, perché il bit di output abbia valore '1' sarà sufficiente che anche uno solo dei due bit di input abbia valore '1'. Si tratta di una operazione corrispondente al nostro 'o' non esclusivo (il vel latino). Esempio: sento un improvviso rumore di vetri rotti in cucina, e penso "accidenti, o è caduta una bottiglia o è caduto un bicchiere". Ebbene, la mia proposizione disgiuntiva "è caduta una bottiglia o è caduto un bicchiere" sarà naturalmente vera se è caduta una bottiglia (se è cioè vera, ha valore '1', la prima delle due proposizioni più semplici che la compongono); sarà vera anche se è vera (ha valore '1') la seconda proposizione ("è caduto un bicchiere"); e resterà egualmente vera se, per malaugurata ipotesi, fossero caduti sia una bottiglia sia un bicchiere. La mia ipotesi - ovvero la proposizione di partenza - sarà però falsa se il rumore, ad esempio, è causato dalla caduta del televisore, o del lume: in questo caso, se cioè entrambe le proposizioni che compongono la disgiunzione hanno valore '0', anche la disgiunzione nel suo complesso avrà valore '0'. Quanto al NOT, il suo funzionamento dovrebbe essere intuitivo: l'operazione NOT avrà come input un solo bit: se il valore dell'input è '0', il valore dell'output sarà '1', e viceversa.
Le operazioni booleane si chiamano così dal nome del matematico inglese George Boole, che verso la metà dell'Ottocento pubblicò un trattato nel quale utilizzava '0' e '1' per rappresentare rispettivamente verità e falsità, e forniva le regole di un calcolo logico basato su tale convenzione. Ma come mai il microprocessore ha bisogno di saper fare 'calcoli logici' di questo tipo? A ben pensarci, niente di strano: molto spesso, le istruzioni di un programma hanno la forma "se si verificano questa condizione e quest'altra condizione, allora fai questo", oppure "se si verifica questa o quella condizione fai quest'altro", o ancora "se non si verifica questa condizione, fai quest'altro ancora". Dunque, è importante che il microprocessore sappia 'calcolare' se una proposizione complessa è vera o falsa, partendo dalla verità o falsità delle proposizioni semplici che la compongono. Nella quarta dispensa scopriremo che le operazioni logiche possono anche aiutarci a formulare richieste per la ricerca di informazioni all'interno di una base di dati.
Cos'altro c'è nella CPU?
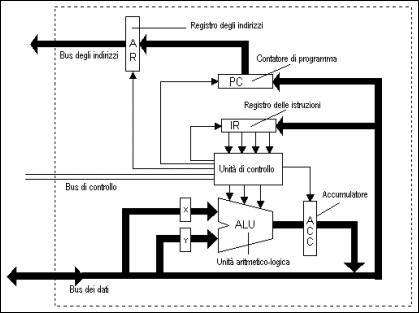
Proviamo adesso a mettere insieme le informazioni che abbiamo acquisito fino ad ora, e a considerare in maniera un po' più organica l'architettura interna di una CPU, aiutandoci attraverso la figura 7. Innanzitutto, troviamo i canali di comunicazione fra la CPU e il resto del computer: il bus dei dati, attraverso il quale arrivano i dati in entrata sui quali effettuare elaborazioni ed escono quelli in uscita, i risultati delle elaborazioni fatte. Un secondo bus, il bus degli indirizzi, ha il compito specifico di occuparsi degli indirizzi di memoria nei quali reperire dati e istruzioni. Di cosa si tratta? Ebbene, la maggior parte della memoria di un computer è in realtà esterna alla CPU, e come abbiamo visto la CPU ha bisogno continuamente di ricevere e inviare dati verso questa memoria. Per poterlo fare, occorre che i dati siano conservati nella memoria in maniera ordinata, e questo avviene attraverso un meccanismo di indirizzi: a 'indirizzi di memoria' diversi corrisponderanno dati diversi. Non ci occuperemo qui dei particolari del meccanismo di indirizzamento, ma possiamo fare un'analogia intuitiva: nello spedire una lettera, ci servirà sia un indirizzo da scrivere sulla busta, sia il testo da scrivere sul foglio, e cioè il contenuto specifico del messaggio. Possiamo pensare all'indirizzo scritto sulla busta come al corrispettivo dell'indirizzo di una certa locazione di memoria, e al testo vero e proprio della lettera come ai dati che sono contenuti in quella particolare locazione di memoria. E' chiaro che, in una situazione in cui dati e indirizzi sono scritti entrambi in forma binaria, è molto importante non fare confusione fra gli uni e gli altri. Quanto al bus di controllo, esso serve soprattutto allo scambio di dati di sincronizzazione: la CPU e le altre componenti del computer devono lavorare in maniera coordinata, e per farlo devono scambiarsi informazioni sullo stato e i tempi di esecuzione dei vari compiti. Ecco allora che la frequenza di lavoro della CPU funziona da vero e proprio orologio (clock) di sistema, che 'segna il ritmo' per il lavoro svolto da tutta la macchina. Una parte importante dei compiti svolti dall'unità di controllo (control unit) consiste proprio nella generazione e nell'invio (attraverso il bus di controllo) dei segnali di controllo e di sincronizzazione. Ma anche il controllo della decodifica e dell'esecuzione delle istruzioni del programma è affidato all'unità di controllo; per questo motivo, essa deve essere in grado di leggere e scrivere dati nel registro delle istruzioni (destinato a tener traccia di quale istruzione il computer sta svolgendo in un determinato momento) e deve comunicare con l'unità aritmetico-logica che, come abbiamo visto, ha il compito di eseguire le operazioni matematiche e logiche. A sua volta, la ALU lavorerà operando sui registri X e Y, che contengono i dati da confrontare o sui quali svolgere le operazioni, e utilizzerà l'accumulatore per tenere man mano traccia dei risultati del suo lavoro.
Un labirinto di sigle e numeriNon pretendiamo di aver dato una rappresentazione completa e rigorosa del lavoro interno alla CPU, ma quanto abbiamo detto finora dovrebbe bastare a farsene un'idea: nel cuore del nostro computer lavora un'attivissima fabbrica impegnata nella continua elaborazione di dati in formato binario; attraverso le vie di comunicazione costituite dai bus, la materia prima arriva dall'esterno sotto forma di dati binari in entrata; viene poi 'lavorata' in accordo con le istruzioni del programma, e viene infine nuovamente 'spedita' verso l'esterno. I ritmi di lavoro della fabbrica sono scanditi dall'orologio della CPU (più 'veloce' è questo orologio, più rapidamente vengono eseguiti i compiti richiesti), e le capacità di elaborazione della fabbrica dipendono direttamente dall'insieme di istruzioni che il processore può riconoscere ed eseguire: ogni programma costruito per essere eseguito da un particolare processore deve essere basato su comandi tratti dal relativo 'set di istruzioni'.
Anche chi non utilizza normalmente un computer sa probabilmente che per identificare le caratteristiche di questa o di quella macchina si utilizzano spesso e volentieri sigle piuttosto arcane: Pentium III 500, Celeron 233, PowerPC G3, e chi più ne ha più ne metta. Ebbene, non di rado le sigle che trovate associate ai diversi computer indicano, oltre al nome del processore, la sua 'frequenza di clock', ovvero la sua 'velocità', espressa in megahertz. Il processore al momento più diffuso è il Pentium della Intel. E un Pentium II 200 avrà un orologio interno che cammina alla velocità di 200 megahertz, e sarà un po' più lento di un Pentium II 300, e parecchio più lento di un Pentium II 400. Nel corso del tempo, la frequenza di clock dei processori è andata continuamente aumentando: pensate che i processori dei primi personal computer IBM avevano una frequenza di clock di poco superiore a 4 megahertz, mentre oggi non è infrequente trovare processori con frequenza di clock pari a 500 megahertz o superiore. Naturalmente, il fatto che la CPU lavori così velocemente porta anche dei problemi: ad esempio, le CPU di oggi, lavorando a una frequenza molto alta ('molto velocemente'), sviluppano anche molto calore. Ed ecco che diventa essenziale 'raffreddare' le CPU; un sistema spesso usato è quello della sovrapposizione alla CPU stessa di una piccola ventola a motore. Altrimenti? Altrimenti, surriscaldata, la CPU potrebbe lavorare male, o guastarsi del tutto. Abbiamo parlato della 'frequenza di clock' come di uno degli indici della velocità di un processore. Ma abbiamo anche accennato al fatto che la potenza effettiva di un processore non dipende solo dalla sua frequenza di clock. Dipende anche dal numero e dal tipo di istruzioni che il processore è in grado di eseguire. Ci sono, a questo proposito, due 'scuole' diverse: i processori che sanno eseguire poche istruzioni molto semplici, ma lo fanno assai velocemente, e i processori che sanno invece eseguire (un po' più lentamente) molte istruzioni diverse e più complesse. Nella prima categoria rientrano i cosiddetti processori RISC, che funzionano con un 'Reduced Instruction Set', un insieme di istruzioni ridotto. Saranno poi i programmatori a dover costruire, mettendo insieme come mattoni le poche istruzioni di base, programmi capaci di effettuare operazioni complesse. Fra i processori basati su una architettura RISC ricordiamo ad esempio i Power PC adottati a partire dagli anni '90 dai computer Macintosh e le famiglie SPARC e UltraSPARC della Sun. Come si è accennato, la seconda categoria è quella dei processori capaci di eseguire direttamente, senza bisogno di programmazione esterna, molte istruzioni diverse. Si tratta dei cosiddetti processori CISC, basati su un 'Complex Instruction Set'. A questa categoria appartengono ad esempio i processori Pentium prodotti dalla Intel.
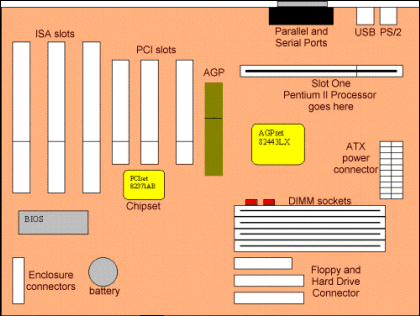
La piastra madreMa torniamo al computer. Ci siamo soffermati finora sul suo cuore, la CPU. Accanto alla CPU ogni computer dispone però di una pluralità di altre componenti, sia 'dentro la scatola' sia al suo esterno (le cosiddette periferiche). Proseguiamo dunque il nostro viaggio all'interno del computer esaminando le componenti che fanno in genere compagnia alla CPU nella 'scatola' principale (detta anche cabinet o chassis) del computer stesso. Innanzitutto, va detto che la CPU è di norma 'incastonata' in una scheda che raccoglie in maniera efficiente e compatta altre componenti fondamentali di ogni computer, come la memoria, le porte di comunicazione, e così via. Si tratta della cosiddetta piastra madre (motherboard). Nella videocassetta della puntata abbiamo 'aperto' un computer, esaminando dal vivo alcune delle componenti fondamentali della piastra madre. Proviamo adesso ad aiutarci con lo schema della figura 10 (che rappresenta una tipica piastra madre del 1999) per capire un po' meglio quali sono le principali componenti elettroniche che fanno compagnia alla CPU all'interno di una piastra madre.
Innanzitutto, dove si trova la CPU? Ebbene, nella piastra madre rappresentata nella figura 8 essa viene inserita nella fessura (slot) situata in alto a destra e marcata come slot one. In altre piastre madri, la CPU può essere invece inserita in un apposito alloggiamento (socket) orizzontale, in genere di forma quadrata. Alcune piastre madri permettono di alloggiare due CPU, che si divideranno il lavoro migliorando le prestazioni del computer. Il fatto che la CPU non sia saldata alla piastra madre, ma inserita in un apposito slot permette all'occorrenza di sostituirla, magari con un modello più recente (che in questo caso dovrà però essere progettato in modo da adattarsi allo slot già esistente). Sopra lo slot nel quale alloggia la CPU, troviamo le porte di comunicazione verso l'esterno; attraverso di esse, i dati possono raggiungere periferiche come stampante, tastiera, mouse, schermo, modem (e magari per questa via altri computer collegati alla rete Internet) e così via. Le porte che vedete indicate sono la porta parallela (utilizzata in genere per il collegamento di una stampante, e per i modelli più economici di scanner) e quella seriale (alla quale possono essere collegati modem, mouse e altri dispositivi), la porta USB (Universal Serial Bus) che costituisce un'alternativa recente e più veloce alla porta seriale, e permette di collegare 'a cascata' molteplici periferiche (fra l'altro schermo, telecamere, scanner, mouse, tastiere.), e la porta PS/2, usata spesso per il collegamento del mouse. Naturalmente, queste porte sono collegate alla CPU attraverso bus di dati che 'corrono' lungo la piastra madre; per evitare una eccessiva confusione dello schema, nell'immagine i bus di dati non sono evidenziati, ma dovete pensare a tutta la piastra madre come percorsa da una fitta ragnatela di strade di comunicazione che ne collegano le diverse componenti. Sotto lo slot del processore troviamo il chip di controllo della AGP (Accelerated Graphic Port); la AGP è un canale dedicato a far circolare in maniera veloce unicamente i dati grafici. Le applicazioni multimediali più recenti - e soprattutto i giochi, particolarmente 'affamati' di grafica ricca e dettagliata - richiedono infatti la generazione e l'aggiornamento continuo delle immagini inviate allo schermo. Nella prima lezione, abbiamo visto come la quantità di bit coinvolta nella gestione di una grafica ad alta risoluzione e di una 'tavolozza' con milioni di colori sia vertiginosamente alta. Ecco allora che un canale dedicato esclusivamente al passaggio dei dati grafici può rivelarsi prezioso, specialmente se affiancato da una buona scheda grafica in grado di aiutare la CPU nella loro gestione. A fianco della AGP, nella parte superiore sinistra della piastra madre rappresentata nella figura 10 troviamo degli altri slot, marcati come ISA e PCI: si tratta di alloggiamenti nei quali possono essere inserite schede di espansione (ad esempio schede sonore, grafiche, video, ecc.). Le sigle ISA e PCI identificano due standard diversi: lo standard PCI (Peripheral Component Interconnect) è più recente, e permette una comunicazione più veloce fra la scheda e la piastra madre; lo standard ISA (Industry Standard Architecture) è più antico, era già presente sui primi personal computer IBM, e pur se meno efficiente, proprio per la sua natura di standard diffuso ha continuato ad essere utilizzato negli anni successivi (spesso nella versione 'estesa' rappresentata dall'Extended ISA o EISA). Nella prima videocassetta (vedi filmato) la scheda sonora inserita da Ugo e Vanilla nel computer è proprio una scheda di questo tipo. Nella terza dispensa parleremo ancora di schede a proposito della connessione di più computer in rete.
MemoriaUn'altra componente fondamentale della piastra madre sulla quale vale la pena di soffermarsi è la memoria. Sappiamo già che la CPU ha bisogno di memoria esterna, di molta memoria esterna sulla quale conservare (nel solito formato digitale!) i dati di lavoro, le istruzioni dei programmi che sta eseguendo, e così via. La memoria utilizzata dalla CPU può essere di vari tipi: memoria 'a portata di mano', disponibile sulla piastra madre, e alla quale è dunque possibile accedere, in lettura e scrittura, in maniera molto veloce, e memoria esterna alla piastra madre, sotto forma di dispositivi di memoria di massa come i floppy disk, i dischi rigidi, i CD-ROM, i DVD ecc. Ci soffermeremo più avanti sulla memoria 'esterna'; per ora concentriamoci su quella direttamente innestata nella piastra madre. A sua volta, essa può essere di vari tipi; il deposito più capiente è quello rappresentato dalla cosiddetta RAM (Random Access Memory), dove mentre usiamo il computer viene conservata, momento per momento, la gran parte dei dati sui quali stiamo lavorando e delle istruzioni relative ai programmi che stiamo usando. Se ad esempio stiamo utilizzando un programma di videoscrittura, la RAM conterrà il testo che stiamo scrivendo (o una larga parte di esso) e i moduli fondamentali del programma che stiamo usando per scriverlo. La RAM è una memoria volatile: i dati vengono conservati sotto forma di potenziali elettrici, e se spegniamo la spina (o se va via la corrente) vanno persi. Nello schema della figura 10, la RAM viene inserita negli alloggiamenti (sockets) in basso a destra, subito sopra i connettori per disco rigido e lettore di floppy disk.
E' necessario però che sulla piastra madre sia presente, a disposizione della CPU, anche una parte di memoria non volatile, contenente una serie di informazioni fondamentali per il funzionamento del computer. Ad esempio, le informazioni su quali siano i dispositivi presenti sulla piastra madre, e su come comunicare con essi. Queste informazioni non possono essere date 'dall'esterno', perché senza di esse la stessa comunicazione con l'esterno è impossibile. Non possono nemmeno essere volatili, perché se lo fossero scomparirebbero al momento di spegnere il computer, e alla successiva riaccensione non sapremmo più come reinserirle, dato che il computer stesso non 'ricorderebbe' più come fare per comunicare con l'esterno. Devono dunque essere a portata di mano, sulla piastra madre, e conservate da una memoria non volatile. Si tratta del cosiddetto BIOS, Basic Input-Output System. La memoria non volatile che conserva questi dati è in genere considerata memoria a sola lettura, o memoria ROM (Read Only Memory), anche se ormai questa denominazione è inesatta: si usano infatti sempre più spesso a questo scopo moduli di memoria non volatile 'aggiornabili' in caso di necessità (flash memory). Nello schema della figura 10, la memoria che contiene il BIOS si trova sulla sinistra, subito sotto gli slot ISA. Talvolta, oltre al BIOS, nella memoria non volatile trovano posto anche veri e propri programmi; è il caso ad esempio di molti computer palmari della nuova generazione (si tratta dell'evoluzione delle cosiddette agendine elettroniche: pesanti qualche centinaio di grammi e in grado di essere portati in una tasca, i computer palmari di oggi sono molto più potenti dei personal computer di sei o sette anni fa). In questo caso, l'installazione in ROM del sistema operativo e dei principali programmi usati consente non solo di averli immediatamente a disposizione, senza aspettare i tempi necessari al loro caricamento da una memoria esterna, ma anche di ridurre il peso della macchina, dato che non servono dispositivi di memoria di massa come dischi rigidi o floppy disk dai quali altrimenti questi programmi dovrebbero essere caricati.
Dal momento che stiamo parlando di memoria, conviene aggiungere una annotazione: abbiamo visto come nella piastra madre trovino posto la RAM e la ROM del computer. Negli ultimi anni, tuttavia, si è diffusa l'abitudine a inserire una memoria autonoma di una certa ampiezza anche all'interno del microprocessore; questa memoria, detta memoria cache, trovandosi a portata diretta della CPU è ancor più veloce della RAM installata sulla piastra madre, ed è quindi in grado di migliorare ulteriormente le prestazioni del sistema. Ma torniamo alle principali componenti che trovano posto nella piastra madre, per concludere il nostro rapido viaggio al suo interno. Non ci manca molto: resta da ricordare che sarà naturalmente necessario un collegamento che porti l'energia elettrica (power connector), e che sarà di norma presente anche una batteria tampone in grado di mantenere aggiornati alcuni dati essenziali (ad esempio la data e l'ora) anche a computer spento.
Dispositivi di memoria di massaLa memoria RAM interna al computer diventa sempre più ampia (sono ormai frequenti personal computer equipaggiati con 64 o 128 Mb di RAM; per una presentazione delle principali unità di misura utilizzate si veda la scheda "Misurare la memoria"), ma come abbiamo accennato si tratta di una memoria volatile, che non è dunque in grado di conservare in maniera permanente dati e programmi. Per quest'ultimo scopo, è bene disporre di depositi di memoria ancor più grandi, dato che vogliamo conservarvi tutti i programmi e tutti i dati che desideriamo avere a nostra disposizione, e non solo quelli che utilizziamo in un dato momento. A questa esigenza rispondono i cosiddetti dispositivi di memoria di massa: disco rigido, floppy disk, CD-ROM, DVD, nastri e cartucce di vario tipo. I floppy disk, ovvero i normali 'dischetti' da computer, sono probabilmente i più familiari: si tratta di piccoli dischi di materiale magnetico inseriti all'interno di un rivestimento di plastica, che all'inizio era flessibile (da qui la caratterizzazione 'floppy') ma che adesso è rigido. Negli ultimi anni, la capacità di immagazzinamento dei floppy disk è aumentata a ritmi assai rapidi; i primi floppy disk erano molto più ingombranti e contenevano 170 Kb di dati; i piccoli floppy disk attuali contengono, nella versione più diffusa, 1.44 Mb di dati.
Secondo molti analisti, tuttavia, l'era dei floppy disk, almeno nella loro forma tradizionale, si avvicina alla fine: da un lato, considerato l'enorme 'ingombro' in termini di bit dei programmi più recenti e di dati che con sempre maggior frequenza non sono solo testuali ma anche sonori o visivi, un supporto capace di contenere pochi megabyte di informazione si rivela spesso inadeguato. Dall'altro, il collegamento in rete (e in particolare a Internet - ce ne occuperemo nella terza e nella quarta dispensa) fornisce un canale nuovo per il trasferimento di programmi e dati verso il computer. Inoltre, l'aumento vertiginoso nella capienza dei dischi rigidi rende inutile 'disperdere' i propri dati su molti dischetti. La sopravvivenza di supporti simili ai floppy disk può dunque essere legata solo alla realizzazione di dischetti molto più capienti; in effetti, stanno conoscendo una certa fortuna supporti che possono essere considerati dei 'discendenti evoluti' dei floppy disk (pur se basati in realtà su tecnologie parzialmente diverse). Fra i più diffusi ricordiamo ad esempio le cartucce ZIP (da 100 Mb) e JAZZ (da 1 Gb) prodotte dalla Iomega, e le cartucce e i nastri prodotti dalla Sysquest. Una categoria ormai diffusissima è quella rappresentata dai CD-ROM; a differenza dei floppy disk e dei nastri, l'informazione è scritta e conservata su un CD-ROM sfruttando non un supporto magnetico, ma un supporto ottico: possiamo pensare a minuscole 'tacche' incise sulla superficie del disco da un raggio laser (quello dell'apparato di scrittura, o masterizzatore), tacche che vengono in seguito lette dal raggio laser del lettore. Si tratta di una procedura del tutto analoga a quella usata nel caso dei Compact Disk musicali. Una volta scritti, i normali CD-ROM sono, come suggerisce il nome, supporti di sola lettura (ricordate? la sigla ROM sta per Read Only Memory). A differenza dei supporti magnetici, non possono dunque essere sovrascritti con nuovi dati. Da alcuni anni esistono tuttavia anche CD-ROM riscrivibili; il loro prezzo è tuttavia piuttosto alto.
La capacità di un CD-ROM non è indifferente: circa 630 Mb di dati, equivalenti a oltre 400 dei tradizionali dischetti floppy. Eppure, se vogliamo usare il CD-ROM come supporto per informazione sonora o visiva (in particolare filmata), questa capacità è ancora poca. Ecco allora che sono nati i DVD (Digital Versatile Disk), apparentemente simili ai CD-ROM ma capaci di contenere quantità ancor maggiori di dati (le capacità dei DVD variano a seconda del loro formato, e - nelle specifiche attuali - possono andare da 4,7 a 17 Gb). Mentre floppy disk, CD-ROM, DVD, nastri e cartucce sono supporti rimovibili (di norma li conserveremo in uno schedario o in un cassetto, e li inseriremo nel computer solo quando ci servono quei particolari dati o quel particolare programma), i dischi rigidi (hard disk) sono in genere fissi, inseriti all'interno della scatola (cabinet) del computer. Si tratta però di una scelta dettata solo da praticità: in effetti, dal punto di vista concettuale sia un floppy disk sia un disco rigido costituiscono memorie di massa esterne rispetto alla RAM ospitata sulla piastra madre. Del resto, esistono anche hard disk rimovibili, alloggiati su appositi scomparti scorrevoli, che pur essendo in genere più ingombranti (e più cari!) dei floppy disk e delle cartucce possono essere, volendo, conservati fuori dalla 'scatola' e inseriti solo al momento opportuno. La caratteristica principale degli hard disk è la capienza: una quindicina d'anni fa, un hard disk da 20 Mb era considerato un lusso, oggi un hard disk sotto i 2 Gb è considerato piccolo, e i 'tagli' da 4 o 8 Gb sono sempre più diffusi (la tendenza all'evoluzione è continua anche in questo settore: può darsi che, quando leggerete queste pagine, le dimensioni di un hard disk di un computer di medie capacità siano ancora maggiori!). Pensate per un momento a cosa questo voglia dire: sappiamo che una cartella dattiloscritta è lunga in media circa 2000 battute; sappiamo anche, dalla prima lezione, che ogni battuta, o carattere, viene codificato attraverso 8 bit, e cioè attraverso un byte. Per codificare una cartella occorrono dunque circa 2 Kb (2 x 1024 byte). Ciò significa che in un floppy disk da 1,44 Mb (pari a 1,44 x 1024 Kb) entrano più di 730 cartelle (volete provare a fare il conto esatto, tanto per tenervi in esercizio?), e in un hard disk da 2 Gb (2 x 1024 Mb) di cartelle dattiloscritte ne entrano oltre un milione. Cosa ce ne facciamo, di tutto questo spazio? Se dovessimo solo scrivere, ne basterebbe molto meno - ma come abbiamo visto possiamo usare bit e byte anche per rappresentare informazione sonora e visiva (a cominciare dalle belle 'finestre' colorate e piene di bottoni che costituiscono ormai la regola anche per i programmi di scrittura), e questa informazione è molto più 'cara' in termini di consumo di memoria. Inevitabilmente, col progressivo miglioramento delle capacità di immagazzinamento e di gestione dell'informazione in formato digitale, ci abituiamo sempre di più alla facilità con la quale possiamo integrare testo, immagini, suoni, filmati, e siamo portati a richiedere una sempre maggiore disponibilità di memoria; siamo insomma ancora ben lontani dal poter dire che disponiamo di tutta la memoria che ci serve. Ricordiamo comunque che queste considerazioni dipendono sempre da quello che vogliamo fare con le risorse che abbiamo a disposizione; in molti casi ad esempio (e non sarebbe difficile trovare esempi fra i numerosi prodotti multimediali in commercio) accade che la maggiore disponibilità di memoria porti a 'coprire' con effetti speciali, suoni e filmati una reale carenza di contenuti. In altri casi, invece (pensiamo ad esempio a basi di dati di materiale filmato), la memoria disponibile non basta a fare tutto quello che sarebbe utile o interessante fare, e ci si deve accontentare di compromessi talvolta poco soddisfacenti. Per concludere la nostra veloce rassegna, vogliamo ricordare un tipo di 'memoria di massa' molto familiare, ma che in genere non riconosciamo come tale: la maggior parte delle carte di credito, le carte Bancomat, le carte telefoniche e molti altri tipi di tesserini (ad esempio, ahinoi, quelli che i dipendenti 'timbrano' all'entrata in ufficio!) possiedono una piccola memoria, su banda magnetica o su chip, che conserva i dati necessari.
Altre perifericheAccanto al processore e alla memoria, un computer ha naturalmente bisogno di una serie di altri dispositivi o periferiche, e all'inizio di questa lezione abbiamo già accennato al ruolo fondamentale dei dispositivi di input e di output. Ricordiamo che i lettori per i supporti di memoria di massa dei quali abbiamo appena parlato possono essere considerati anch'essi dispositivi di input e output, giacché servono al computer a leggere (input) e scrivere (output) dati. Vogliamo provare a riepilogare brevemente alcuni degli altri dispositivi normalmente collegati al computer, riassumendone sinteticamente le funzioni? La tastiera è il dispositivo di input probabilmente più importante. Serve a immettere nel computer testo e numeri (per velocizzare quest'ultima operazione, le tastiere includono di norma un particolare tastierino numerico), ma anche a guidare, attraverso la pressione dei tasti opportuni, lo svolgimento dei programmi.
Per quest'ultimo scopo, alcuni tasti hanno una particolare importanza: innanzitutto le frecce, tasti direzionali che controllano di norma lo spostamento del cursore sullo schermo (il cursore è un 'oggetto' virtuale e non fisico, e compare nelle schermate di lavoro di molti programmi - ad es. programmi di videoscrittura - ad indicare il punto del testo sul quale si sta al momento operando). E poi i tasti funzione, presenti di norma nell'area superiore o in quella laterale della tastiera: si tratta di tasti la cui funzione varia da programma a programma, e che vengono in genere fatti corrispondere ai comandi più frequentemente usati. Una convenzione piuttosto diffusa collega il primo tasto funzione (F1) all'attivazione dell'aiuto in linea (help) del programma. Il mouse affianca la tastiera come dispositivo di input, in particolare quando si lavora all'interno di ambienti o sistemi operativi ad icone (ne parleremo più diffusamente in seguito). Al movimento del mouse su un piano (molto spesso quello del 'tappetino' o mousepad) viene fatto corrispondere il movimento del puntatore nello schermo. Il puntatore del mouse costituisce un altro familiare 'oggetto virtuale' che ci aiuta a selezionare aree e oggetti nello schermo; anche sulla funzione del cursore, che rappresenta un po' il nostro 'alter ego' nello 'spazio virtuale' aperto da un programma, avremo modo di soffermarci in seguito. Il movimento del mouse viene comunicato al computer attraverso i segnali inviati da sensori collocati intorno alla pallina posta sulla superficie inferiore del mouse stesso. Il mouse ha sulla superficie superiore uno o più tasti, alla cui pressione il programma fa corrispondere 'azioni' sugli 'oggetti' situati nell'area dello schermo indicata dal puntatore. Talvolta, il mouse viene sostituito da dispositivi quali la trackball (una sorta di 'mouse rovesciato', che permette il controllo dei movimenti del puntatore attraverso la rotazione di una pallina) o il trackpoint (i movimenti del puntatore sono controllati attraverso la pressione nelle varie direzioni di un piccolo bottone di gomma), utilizzato soprattutto nei computer portatili. Sempre nei portatili, possiamo trovare il touchpad, un'area di forma rettangolare sensibile al tatto: il movimento del puntatore è in questo caso controllato dal movimento del dito sul touchpad. Anche il joystick è un dispositivo di input concettualmente non troppo lontano dal mouse; è molto usato nei giochi: la direzione di spostamento della levetta del joystick viene fatta in genere corrispondere alla direzione del movimento del personaggio o del veicolo da noi controllato, e la pressione del bottone corrisponde a specifiche azioni all'interno del gioco (ad esempio, al 'fuoco' di un'arma).
Fra i dispositivi di input, abbiamo già parlato nella prima dispensa dello scanner, utilizzato per far acquisire al computer immagini e (con l'aiuto di un programma OCR per il riconoscimento automatico dei caratteri) testi a stampa. Un dispositivo di input relativamente meno diffuso (ma utilissimo ad esempio per lavori grafici) è la tavoletta grafica; i movimenti di una sorta di 'penna' sulla sua superficie vengono registrati da appositi sensori e vengono fatti corrispondere ai movimenti di una 'penna virtuale' sullo schermo del computer. In associazione con un programma grafico, la tavoletta grafica permette di 'disegnare' al computer.
Fra i dispositivi di output, ricordiamo subito lo schermo. Molto spesso si tratterà di un tradizionale monitor (di dimensioni variabili; proprio come nel caso dei televisori, le dimensioni vengono misurate in pollici, e le più frequenti vanno dal 'piccolo' 14" al 'grande' 21"). Nel caso di un computer portatile avremo invece a che fare con uno schermo a cristalli liquidi delle dimensioni generalmente comprese fra i 9" e i 13"; gli schermi a cristalli liquidi possono essere basati sulla tecnologia dual scan (più economica ma di qualità lievemente inferiore) o sulla tecnologia a matrice attiva (più cara ma di miglior resa). Negli ultimi anni si stanno diffondendo monitor a cristalli liquidi anche per l'uso con computer da tavolo, in alternativa ai monitor tradizionali. Sono per ora piuttosto cari (la produzione di schermi a cristalli liquidi di grandi dimensioni è abbastanza costosa), ma garantiscono una elevata qualità dell'immagine, oltre a risultare più riposanti per la vista.
L'altro fondamentale dispositivo di output è la stampante. In questo campo, le tecnologie fondamentali sono tre: stanno ormai scomparendo le vecchie stampanti ad aghi, a favore delle stampanti laser (lievemente più care, ma preferibili per la stampa di qualità di un alto numero di copie) e di quelle a getto d'inchiostro (più economiche, soprattutto nella stampa a colori; la relativa tecnologia ha compiuto negli ultimi anni notevoli passi avanti). La qualità delle stampanti è talmente migliorata nel tempo da relegare a un mercato molto specializzato i cosiddetti plotter, stampanti grafiche a 'pennini' utilizzate per la progettazione e il disegno architettonico. Un discorso a parte meriterebbero le periferiche musicali e per l'acquisizione audio-video; ne abbiamo però già accennato nella prima dispensa, alla quale rimandiamo. Il piccolo elenco che abbiamo cercato di stilare non esaurisce certo le periferiche possibili; di alcune altre periferiche (ad esempio di quelle che permettono la navigazione in ambienti di realtà virtuale) avremo occasione di parlare in futuro, altre, a volte molto specializzate, le incontrerete probabilmente nel vostro lavoro.
Hardware e software
All'inizio, i più diffusi programmi per computer ricadevano in poche categorie abbastanza determinate: programmi di calcolo di vario genere, utilizzati soprattutto per il lavoro scientifico, giochi (non sottovalutate mai l'importanza dei giochi: si tratta del campo in cui sono state sperimentate per la prima volta alcune fra le tecnologie più innovative, un campo che si è rivelato decisivo per la diffusione di massa dei personal computer, in particolare fra bambini e ragazzi), e poi programmi di videoscrittura (word processor), fogli elettronici (spreadsheet; si tratta dei programmi utilizzati per creare tabelle di dati, in genere numerici: ad esempio, un bilancio contabile), e programmi per la creazione e gestione di 'schedari', ovvero basi di dati (i cosiddetti database).
Col tempo, e con il miglioramento delle capacità dei computer, queste categorie si sono moltiplicate, tanto da rendere ormai praticamente impossibile una classificazione esaustiva dei vari tipi di software esistente. Ricordiamo solo, al volo: programmi grafici, programmi di manipolazione sonora e di manipolazione video, programmi di comunicazione, programmi per la navigazione su Internet, programmi didattici, editoria multimediale, e così via.
Il software più importante: il sistema operativoDi un tipo particolare di programmi, tuttavia, è bene parlare subito, almeno in termini generali: si tratta dei cosiddetti sistemi operativi (operating systems). Abbiamo già visto che il BIOS comprende una programmazione di base che mette il processore in grado di 'conoscere' le principali componenti installate sul computer e di comunicare con esse; attraverso l'aiuto del BIOS il computer 'riconosce' ad esempio l'esistenza del lettore di floppy disk e del (o dei) dischi rigidi. Se il BIOS ha in un certo senso il compito di rendere il nostro computer 'cosciente di sé' e capace di far circolare informazione al proprio interno, esso tuttavia non svolge se non in piccola parte un altro compito essenziale: quello di rendere il computer capace di comunicare con noi, ovvero con l'utente. Non è un compito facile. Infatti, non vogliamo semplicemente rendere il computer capace di riconoscere le istruzioni impartite da un esperto informatico. Il nostro obiettivo è più ambizioso: costruire un ambiente di lavoro che permetta anche a un non esperto di interagire col computer in maniera semplice e intuitiva. Non ci basta insomma che il computer sia in grado di comunicare con noi: vogliamo, per quanto possibile, che esso impari a comunicare con noi 'usando la nostra lingua', usando cioè convenzioni di comunicazione per noi familiari e intuitive. Il sistema operativo ha proprio questa funzione fondamentale. Ci occuperemo diffusamente dei sistemi operativi anche nella quinta dispensa; in questa sede, ci limitiamo ad alcune considerazioni di base. All'inizio, i sistemi operativi erano basati sull'idea della comunicazione linguistica; i sistemi operativi a caratteri, come MS-DOS (il Disk Operating System della Microsoft) o UNIX, si basano appunto sull'idea che l'utente impartisca i propri comandi in forma 'scritta', utilizzando la tastiera. Così ad esempio in DOS per la visualizzazione dell'indice del contenuto di un dischetto si usa il comando 'dir', per la preparazione di un dischetto vergine si usa il comando 'format', per la visualizzazione e la modifica della data e dell'ora di sistema si usano rispettivamente i comandi 'date' e 'time', e così via (si veda la tabella "Il DOS, alcuni fra i comandi principali"). Col tempo, tuttavia, l'evoluzione dei sistemi operativi ha conosciuto una importante evoluzione proprio nel tipo di interfaccia usata: al posto delle interfacce a caratteri sono comparse le cosiddette interfacce ad icone o grafiche (GUI, Graphical User Interface). Il primo sistema operativo con una interfaccia grafica è stato sviluppato negli anni '70 nei laboratori di Palo Alto della Xerox, ma la loro diffusione si deve soprattutto ai computer Apple: prima l'ormai dimenticato Apple Lisa, poi, a partire dal 1984, il diffusissimo Macintosh hanno adottato sistemi operativi ad icone che hanno fatto scuola. Interfacce grafiche ad icone avevano anche il Commodore Amiga - un computer che è stato fra i più interessanti ed avanzati prodotti dell'industria informatica degli anni '80 -, l'Atari ST, e uno dei primi computer basati su un processore RISC, l'Acorn Archimedes. Ben presto anche IBM e Microsoft hanno seguito la tendenza: la prima con il sistema operativo OS/2, la seconda con le varie versioni di Windows, al momento il sistema operativo largamente più diffuso.
Accanto alla funzione di comunicazione con l'utente, il sistema operativo svolge altri compiti importanti: ad esempio, integra le poche e sommarie conoscenze sull'architettura del sistema che il microprocessore ricava dal BIOS con informazioni dettagliate sul tipo di periferiche usate, sulle loro capacità, sulle istruzioni necessarie a garantirne il migliore funzionamento. Inoltre, mette a disposizione dei diversi programmi che - a seconda delle sue specifiche necessità - l'utente può di volta in volta eseguire, una serie di 'strumenti di base' comuni che ne semplificano l'utilizzazione. Il sistema operativo è dunque il primo e più importante programma (a rigore non si tratta ormai più di un programma singolo, ma di un insieme integrato di programmi e strumenti) a disposizione del computer. Ecco perché, una volta presa 'coscienza di sé' attraverso l'acquisizione delle informazioni contenute nel BIOS, la prima operazione compiuta dal computer all'accensione è il caricamento del sistema operativo, presente in genere sul disco rigido. Come si è accennato, sul concetto di sistema operativo avremo occasione di tornare più volte nelle prossime lezioni, sottolineandone fra l'altro il rilievo teorico e culturale. Un sistema operativo, infatti, non è solo una realizzazione ingegneristica, ma rispecchia in qualche misura la 'filosofia' che scegliamo di adottare nel nostro rapporto con il computer: i tipi di compiti che ci interessa far svolgere alla macchina, le tipologie di utente che con essa devono interagire, i modelli di comunicazione adottati. Bisogna dunque guardarsi dal considerare il sistema operativo come una sorta di 'dato' tecnologico: esso è piuttosto il risultato di un processo che ha sì aspetti tecnici ed ingegneristici, ma anche fondamentali aspetti culturali e comunicativi.
ConclusioneQuesta dispensa sarà probabilmente risultata molto 'densa', e forse di lettura un po' faticosa. Siamo tuttavia convinti che valesse la pena di fare questo sforzo: se ci avete seguito fin qui, il computer non dovrebbe sembrarvi più come una sorta di 'scatola nera' dal funzionamento quasi magico. Dovreste vederlo piuttosto come una realizzazione ingegneristica certo complessa (e in continua evoluzione), ma i cui principi basilari di funzionamento non sono necessariamente e totalmente incomprensibili per i 'comuni mortali'. E questo è importante: se in generale è infatti utile cercare di capire almeno per sommi capi come funzionano gli oggetti che ci sono intorno, questo è particolarmente importante nel campo dell'informatica. Il computer ha infatti assunto un ruolo fondamentale per la nostra vita culturale, economica, produttiva; limitarsi ad usarlo passivamente, delegando a una 'casta' di esperti ogni comprensione del suo funzionamento, può rivelarsi una mossa sbagliata sotto molti rispetti, non ultimi quelli collegati alle nostre prospettive di lavoro e alla nostra capacità di partecipazione sociale e politica al mondo che ci circonda.
Esercizi
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Alcuni riferimenti bibliografici
|
 |