Nella dispensa precedente abbiamo supposto che per costruire una
macchina intelligente sia 'sufficiente' trovare le regole con cui il nostro
cervello elabora i simboli mentali, e trasformarle in un programma per computer.
Tuttavia, se 'guardiamo' dentro un cervello non riusciamo a trovare qualcosa di
immediatamente simile a un programma. Non abbiamo alcuna idea di come il
cervello rappresenti internamente i suoi programmi, e dunque non abbiamo modo di
confrontare i programmi che potremmo scrivere noi con quelli eseguiti
(presumibilmente) dal cervello. Ma allora, ammesso che sia realmente possibile
realizzarlo, come possiamo essere sicuri che un computer sia effettivamente
intelligente?
Una via di uscita molto elegante da questa situazione di stallo
è stata proposta, ancora una volta, da Alan Turing che, tra i tanti meriti,
può sicuramente esser fregiato del titolo di 'padre dell'intelligenza
artificiale'. In un articolo del 1950 intitolato Macchine Calcolatrici e
Intelligenza , il grande scienziato inglese inizia proprio con questa frase:
"Mi propongo di considerare la domanda: "Possono le macchine
pensare?"". Dopo avere espresso la sua scarsa fiducia nei tentativi di
definizione astratti, egli propone un metodo per rispondere al quesito che si
basa su una specie di gioco, il gioco dell'imitazione.Una possibile soluzione al
problema di decidere se un computer sia intelligente o meno potrebbe consistere
nel trovare una definizione precisa di 'intelligenza', una specie di elenco che
dica: l'intelligenza è questo e quest'altro. Una volta in possesso di questa
definizione potremmo prendere il computer che 'asserisce' di essere
intelligente, e vedere se veramente presenta tutte le caratteristiche presenti
nell'elenco. Sfortunatamente, tra gli studiosi dell'intelligenza (psicologi,
filosofi, neuroscienziati, antropologi etc.) non vi è molto consenso su tale
definizione. Ogni volta che se ne è proposta una, qualcuno è saltato sulla
sedia dicendo: eh no, non avete tenuto conto di questo aspetto! Oppure: avete
dato troppa importanza a quest'altro aspetto! E così via.
Si tratta di un gioco a cui partecipano tre persone tra loro
estranee. Due di loro, di sesso opposto, sono i candidati; il terzo (di cui è
indifferente il sesso) è l'interrogante. L'interrogante viene chiuso in una
stanza in modo che non abbia alcun contatto, di nessun tipo, con gli altri. Lo
scopo del gioco per l'interrogante è capire quale dei due candidati sia l'uomo
e quale la donna. A tale fine egli può solo fare delle domande ai candidati
mediante una telescrivente (oggi useremmo magari un computer collegato in rete).
Scopo dei candidati invece è ingannare l'interrogante. Simmetricamente le loro
risposte saranno 'telescritte'. Questo vincolo è ovviamente dettato dalla
necessità di evitare che l'aspetto, la voce, o persino la calligrafia dei
candidati possano influenzare il giudizio. Ora, dice Turing, immaginiamo di
mettere al posto di uno dei due candidati una macchina 'presunta intelligente'.
Se l'interrogante non è in grado di capire quale tra i suoi interlocutori sia
un uomo e quale una macchina, allora possiamo asserire tranquillamente che la
macchina è intelligente.
È importante che le domande dell'interrogante durante il gioco
riguardino vari argomenti e abbiano un carattere generale. Infatti se
chiedessimo "quanto fa 10 elevato alla 23 diviso 5" pensando che la
macchina risponderebbe pressoché subito mentre l'uomo (o la donna)
impiegherebbe molto più tempo, potremmo essere tratti in inganno da un trucco
banale: basterebbe programmare il computer per aspettare alcuni minuti prima di
rispondere a domande sui numeri. Mentre se una macchina fosse veramente in grado
di superare il test rispondendo a domande sulla poesia, o sui suoi gusti
gastronomici, o sull'amore, allora il successo ci dovrebbe far ammetter che essa
sia intelligente.
Il gioco dell'imitazione nella versione con il giocatore
artificiale è divenuto noto come test di Turing, e secondo il suoi ideatore
sarebbe in grado di sostituire in tutto e per tutto la domanda astratta
"Possono pensare le macchine?". Esso è cioè un test per
l'intelligenza. A dire il vero questa convinzione è stata sottoposta a diverse
critiche. Ad esempio, quando nella metà degli anni '60 una grande quantità di
persone furono tratte in inganno da un semplice programma - noto come Eliza - in
grado di sostenere brevi e banali conversazioni in inglese, molti ritennero che
si fosse confutata l'adeguatezza del test. Tuttavia ancora oggi la maggior parte
degli studiosi di intelligenza artificiale è incline a credere cha il
superamento del test di Turing, opportunamente condotto, costituisca, se non una
prova definitiva, almeno un forte indizio dell'intelligenza di un computer.
Tra i molti programmi sviluppati nell'ambito dell'intelligenza
artificiale, quello che ha goduto della massima notorietà è senza dubbio Eliza,
realizzato nel 1964 da Joseph Weizenbaum, a quei tempi giovane ricercatore del
MIT. Si trattava di un programma, piuttosto semplice, che simulava una limitata
competenza linguistica in inglese, ma che non aveva alcuna pretesa di
comprendere realmente il linguaggio. Per semplificare il suo compito Weizenbaum
aveva pensato di circoscrivere notevolmente l'ambito di argomenti su cui di
volta in volta il suo programma era in grado di conversare.
Siccome ogni conversazione deve avere un argomento, il programma
era organizzato su due piani: il primo conteneva l'analizzatore del linguaggio,
il secondo un copione. In questo modo, Eliza poteva essere messo in grado di
sostenere una conversazione su come si cucinano le uova, o sulla gestione di un
conto corrente bancario e così via. Ogni particolare copione permetteva a Eliza
di assumere un ruolo diverso nella conversazione. Il primo copione che
Weizenbaum diede ad Eliza fu quello per recitare la parte di uno psicoterapeuta
di scuola rogersiana. Gli psicoterapeuti di questa scuola durante una seduta
cercano di intervenire il meno possibile e, quando lo fanno, spesso si limitano
a ripetere le affermazioni del paziente in forma di domanda. Si trattava dunque
di un comportamento linguistico abbastanza semplice da simulare.
Una volta terminato il programma, Weizenbaum lo installò su un
computer del suo istituto, e iniziò a farlo provare da varie persone, tra cui
la sua stessa segretaria. Questa è la traduzione italiana di una conversazione
tra Eliza, o meglio Doctor, come fu soprannominato il programma nella sua veste
da psicoterapeuta, e una ragazza:
Ragazza: Gli uomini sono tutti uguali.
Eliza: In che senso
Ragazza:Trovano sempre il modo di tormentarci.
Eliza: Può farmi un esempio?
Ragazza: Beh è il mio ragazzo che mi ha fatto venire qui.
Eliza: È il suo ragazzo che l'ha fatta venire
Ragazza: Dice che sono depressa.
Eliza: Mi dispiace sentire che è depressa.
Ragazza: È vero. Sono infelice.
Eliza: Pensa che il fatto di venire qui l'aiuterà a non essere infelice?
Con grande stupore di
Weizenbaum, Eliza ebbe un enorme successo.
La gente che conversava con lui credeva veramente di avere a che fare con uno
psicoterapeuta e provava persino sollievo dopo le sedute! Uno psichiatra,
Kenneth Colby, scrisse persino che di lì a pochi anni programmi come Eliza
sarebbero stati pronti per l'uso clinico. Lo stesso Colby poco dopo realizzò un
programma non dissimile da Eliza, che battezzò Parry. Parry simulava il
comportamento linguistico di un paranoico. E anche lui ebbe un buon successo,
tanto da riuscire ad ingannare molti psichiatri che, dopo averlo intervistato
via telescrivente, si dissero convinti di avere avuto a che fare con un vero
paranoico. Ad un certo punto fu organizzata persino una seduta di Parry da Eliza!
Sembrava dunque che questi due programmi avessero superato il
test di Turing. In realtà né Eliza né tantomeno Parry erano dotati della sia
pur minima intelligenza. Si trattava in entrambi i casi di un insieme di trucchi
di programmazione (ad esempio Eliza nella maggior parte dei casi prende le
affermazioni del paziente e le rovescia in forma di domanda cambiando
semplicemente i pronomi, cosa che in inglese, peraltro, è piuttosto semplice)
che facevano affidamento sulla credulità dei loro interlocutori. E a ben vedere
nessuno dei due programmi avrebbe mai superato il test nella forma in cui Turing
lo aveva immaginato. Le persone che credettero veramente nelle capacità di
Eliza infatti, non prestavano attenzione a ciò che il programma diceva loro, ma
erano piuttosto intenti a sfogarsi. E inoltre l'ambito della conversazione era
tanto ristretto da non essere valido per il test. In ogni caso, se volete
provare a fare due chiacchere con Eliza o Parry potete scaricarne una versione
al seguente indirizzo (utilissimo anche per il reperimento di molti altri
programmi di intelligenza artificiale): http://www.cs.cmu.edu/Groups/AI/areas/classics.
L'elaborazione
del linguaggio naturale
Nell'affrontare il tema dei fondamenti teorici
dell'intelligenza artificiale abbiamo detto che la capacità di
elaborare simboli è alla base del comportamento intelligente.
L'esempio di elaborazione simbolica che in misura maggiore
caratterizza gli esseri umani è senza dubbio il linguaggio verbale.
In realtà la capacità di comunicare mediante
simboli non è una prerogativa della nostra specie. Tuttavia nessuna
specie vivente conosciuta è dotata di un sistema di comunicazione
simbolica così sviluppato e complesso come il linguaggio verbale.
Secondo molti studiosi, dobbiamo proprio alla comparsa del
linguaggio, avvenuta tra 100 e 200 mila anni fa, quell'enorme salto
evolutivo che ha differenziato l'homo sapiens, la nostra specie, da
tutte le altre specie di ominidi. Linguaggio e intelligenza,
infatti, sono fenomeni strettamente interconnessi. Lo stesso test di
Turing assume che un eventuale computer intelligente deve sapere
comunicare mediante il linguaggio naturale, come facciamo noi esseri
umani.
È dunque ovvio che sin dalle origini uno degli
obiettivi principali dell'intelligenza artificiale sia stato lo
sviluppo di programmi in grado di produrre e comprendere discorsi in
linguaggio naturale. A dire il vero, i primi passi mossi in questa
direzione furono motivati più da interessi pratici che da stimoli
teorici. Infatti, alcuni fra i primi finanziamenti che arrivarono ai
progetti di ricerca nell'allora nascente campo dell'intelligenza
artificiale furono attratti dalla prospettiva di sviluppare dei
sistemi di traduzione automatica tra varie lingue, la cui
applicazione commerciale era (ed è ) evidente. Tuttavia dopo un
iniziale e ottimistico entusiasmo, il compito di insegnare le lingue
ai computer si dimostrò tanto complesso da far abbandonare il
miraggio di un traduttore automatico. Ma le ricerche sulla
elaborazione del linguaggio naturale (natural language processing)
proseguirono egualmente, e ancora oggi costituiscono uno dei settori
di punta dell'intelligenza artificiale, oltre ad essere divenuti
oggetto di una ulteriore disciplina che si chiama linguistica
computazionale. Le
grammatiche di Chomsky e l'analisi automatica del linguaggio naturale
L'elaborazione automatica del linguaggio naturale
prende le mosse dalla teoria linguistica di Noam Chomsky, una delle
personalità scientifiche più rilevanti del nostro secolo. In
questa sede naturalmente non potremo dilungarci su tutti i
complicati aspetti della teoria chomskiana, che peraltro ha subito
nel corso degli anni numerose revisioni da parte del suo stesso
artefice e dei suoi tanti seguaci.
In estrema sintesi possiamo dire che secondo Chomsky
la capacità che ogni essere umano ha di capire e produrre frasi e
discorsi nella sua lingua è dovuta ad un insieme di conoscenze
presenti nella sua mente: definiamo questo insieme di conoscenze
implicite competenza linguistica. È evidente che tale competenza è
almeno in parte inconsapevole: infatti la maggior parte delle
persone sono in grado di produrre e capire le frasi corrette, così
come di individuare immediatamente gli usi scorretti della loro
lingua, pur senza sapere il modo in cui questo avviene. Inoltre,
sostiene Chomsky, la maggior parte di questa competenza deve essere
innata: non si spiegherebbe altrimenti la velocità con cui un
bambino in pochi anni riesca a parlare una lingua in modo
sostanzialmente corretto semplicemente imitando chi lo circonda.
La competenza linguistica, a sua volta, si suddivide
in tre componenti: competenza fonologica, competenza sintattica e
competenza semantica. La prima riguarda la capacità di un parlante
di produrre e capire i suoni della lingua parlata; la seconda
riguarda la capacità produrre o riconoscere frasi grammaticalmente
corrette; la terza riguarda la capacità di assegnare o di estrarre
significato dalle frasi. Tutte queste capacità derivano dalla
presenza nelle mente di un insieme di regole ben precise, che sono
simili alle regole di un sistema formale.
Per vari motivi, nella loro teoria della lingua
Chomsky e i suoi seguaci hanno assegnato un ruolo prioritario alla
competenza sintattica. È grazie ad essa che ogni parlante è in
grado di percepire immediatamente che
(a) "il gatto mangia il topo"
è una frase grammaticalmente corretta, mentre
(b) "il gatto topo il mangia"
non lo è. Come detto, questo riconoscimento è
determinato dal fatto che nella formazione di una frase (o nel
processo simmetrico di comprensione di una frase) vengono seguite
delle regole formali che complessivamente costituiscono la
grammatica di una lingua. Tali regole, che si articolano in diversi
gruppi (o componenti), vengono applicate (non necessariamente in
modo sequenziale) per arrivare alla costruzione di frasi corrette, o
alla verifica di frasi pronunciate da altri parlanti. Il gruppo
principale di regole (o componenti di base) della teoria chomskiana
determina la struttura generale di una frase e dà conto del fatto
che ognuno è in grado di raggruppare in modo intuitivo le parole
che la compongono in gruppi funzionali detti sintagmi. Ad esempio,
chiunque tende a raggruppare le parole dell'esempio (a) in questo
modo: "Il gatto" - " mangia il topo". Ma
vediamo, attraverso un esempio concreto, la forma che possono
assumere queste regole. F -> SN - SV SN
-> DET - N SV -> V - SN DET -> il N
-> gatto, topo V -> mangia Così espresse,
le regole possono sembrare un po' oscure. Ma acquistano subito il loro
significato se le interpretiamo in questo modo:
-
una frase (F - nel nostro
eempio, 'il gatto mangia il topo')
consiste di un sintagma nominale (SN - nel nostro esempio 'il gatto')
seguito da un sintagma verbale (SV, nel nostro esempio 'mangia il topo')
-
un sintagma nominale (SN, nel nostro esempio 'il gatto'
oppure 'il topo') è costituito da un determinante (DET, nel nostro esempio
'il') e da un nome (N, nel nostro esempio 'gatto' o 'topo')
-
un sintagma verbale (SV, nel nostro esempio 'mangia il
topo')
è costituito da un verbo (V - nel nostro esempio 'mangia') seguito da un
sintagma nominale (SN, nel nostro esempio 'il topo') · un determinante (DET)
è un elemento del seguente insieme: (il)
-
un nome (N) è un elemento del seguente insieme: (gatto,
topo)
-
un verbo (V) è un elemento del seguente insieme: (mangia)
Le regole vengono applicate per passi successivi a
partire dalla prima (anche se alcune regole possono essere applicate
più volte se necessario) fino ad arrivare a una regola che a destra
contenga un simbolo terminale, un simbolo cioè che non può essere
ulteriormente scomposto (nel nostro caso hanno questa forma le
ultime tre regole): in questo modo esse generano una frase completa.
Possiamo verificare senza troppi sforzi che queste regole ci
consentono di generare la frase (a) e non la frase (b). Per
rendercene conto usiamo la classica rappresentazione ad albero con
cui di norma i linguisti rappresentano la struttura sintagmatica di
una frase.
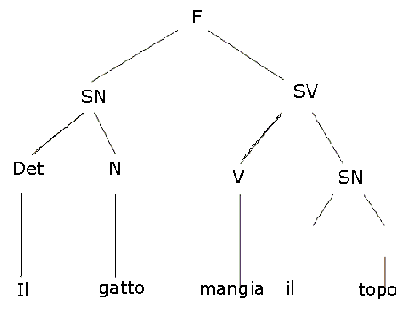
Figura 1 - La rappresentazione ad albero della
struttura sintagmatica di una frase
Per quanti tentativi facciate non sarete in grado di
generare la frase "il gatto topo il mangia". D'altra parte
non potreste nemmeno generare una frase come "il gatto il topo
mangia", che suona un po' strana, ma è comunque ammissibile in
italiano. Per questo alle regole generative del componente di base
nelle teoria di Chomsky si affiancano altre regole che applicate
alla frase standard la trasformano in diversi modi corretti (ad
esempio rendono la frase passiva: "Il topo è mangiato dal
gatto").
Appare evidente che un programma non avrebbe
difficoltà ad usare regole come queste per generare frasi. E
simmetricamente un programma potrebbe, data una frase, analizzarla
al fine di ricostruire la sua struttura e verificare se essa è tra
quelle ammesse dalla grammatica: questi programmi si chiamano parser,
o analizzatori sintattici, e sono alla base di tutti i sistemi di
elaborazione del linguaggio naturale. Se dunque fosse possibile
costruire grammatiche generative-trasformazionali (così vengono
chiamate) per una data lingua, avremmo un metodo efficiente ed
elegante per realizzare un programma in grado di elaborare almeno la
sintassi di quella lingua. Tuttavia il compito di costruire queste
grammatiche per le lingua storico naturale si è rivelato assai più
improbo di quanto Chomsky non ritenesse. Attualmente esistono
porzioni di grammatica abbastanza complete per varie lingue
(soprattutto l'inglese), ma si è ben lontani dall'obiettivo di una
formalizzazione completa. Il
problema del significato
Abbiamo visto che, almeno in teoria, è possibile
realizzare un programma in grado di generare o di analizzare le
frasi grammaticalmente corrette di una lingua. Ma come forse avrete
capito, tale programma di fronte a una frase come "Il topo
mangia il gatto" non farebbe una piega. Infatti questa è un
frase grammaticalmente corretta. Tuttavia, a meno che non compaia in
una favola o in un racconto fantastico, chiunque la giudicherebbe
priva di senso.
Per fare in modo che un computer capisca veramente
il linguaggio naturale, dunque, dobbiamo essere in grado di
specificare anche il significato delle parole: la competenza
semantica. A questo punto però, i problemi teorici si fanno assai
più ardui. In primo luogo: che cosa è il significato? Su questo
problema i filosofi hanno lungamente discusso, almeno dai tempi di
Aristotele. E ancora oggi nessuno ha proposto una teoria
soddisfacente di cosa sia il significato. Vogliamo far notare, per
inciso, che il problema del significato è un po' il convitato di
pietra che si nasconde nell'intero edificio concettuale
dell'intelligenza artificiale. Infatti, quando abbiamo detto che per
la teoria rappresentazionale della mente il pensiero corrisponde
alla manipolazione di simboli secondo regole, non ci siamo
preoccupati di dire che cosa e in che modo questi simboli
significhino. Anzi, più volte si è ripetuto che per quanto attiene
alle computazioni, ciò che conta è solo la forma dei simboli e
delle configurazioni di simboli, ovvero la sintassi. Ma allora come
mai quando parliamo sentiamo di esprimere qualche cosa che va al di
là della semplice sequenza di suoni che esce dalla nostra bocca? E
come è possibile che nella maggior parte dei casi le nostre frasi
si riferiscano a oggetti e a situazioni del mondo, e che gli altri
possano ad esempio verificare se ciò che diciamo corrisponde alla
realtà?
Al problema filosofico di specificare che cosa sia,
in ultima analisi, il significato o i concetti che abbiamo nella
mente sono state date diverse soluzioni, su cui non possiamo
soffermarci. Tuttavia, possiamo provare a delineare, almeno nei suoi
aspetti generali, la strategia che è stata seguita nel campo
dell'intelligenza artificiale per dare una semantica ai computer.
Cominciamo con il significato delle parole, o
significato lessicale: esso può essere descritto mediante la
scomposizione in una serie di componenti più semplici, in questo
modo:
gatto à oggetto+fisico+animato…
I puntini stanno ad indicare che la descrizione
dovrebbe proseguire per molti (quanti?) componenti prima di esaurire
il significato della parola. Naturalmente tale descrizione dovrebbe
tenere conto dei casi di ambiguità, di sinonimia etc. Ma è
possibile immaginare dei sistemi per farlo.
Per descrivere il significato delle frasi e le
relazioni logiche tra più parole, poi, si è fatto ricorso alla
logica. La logica studia il modo in cui viene condotto il
ragionamento valido, ovvero il modo in cui a partire da premesse
valide possono essere tratte conclusioni valide. Per fare questo, a
partire dalla fine del secolo scorso i logici hanno pensato di
costruire dei linguaggi artificiali formalizzati (ancora!) per
evitare di incorrere nei rischi di ambiguità del linguaggio
naturale. L'idea in sostanza è quella di individuare la forma
logica sottostante alle frasi del linguaggio naturale (in cui essa
viene in un certo senso mascherata) in un linguaggio rigoroso e
soprattutto governato da regole precise. Per formalizzare le
asserzioni (o enunciati) del linguaggio naturale, si è pensato di
operare in questo modo: prendiamo la frase "il gatto è
nero". Essa esprime una proprietà relativa ad un oggetto
(animato!): l'oggetto è "gatto" e la proprietà è
"essere nero". Per mettere in evidenza questa struttura
potremmo riscrivere l'enunciato in questo modo:
(a) essere nero ( gatto )
L'enunciato (a) dice o predica che la proprietà
"essere nero" si applica ad un oggetto e che questo
oggetto è un "gatto". La parte di (a) che specifica la
proprietà viene chiamata predicato; la parte che indica a chi si
applica la proprietà si chiama argomento. Una volta fatta questa
traduzione della frase italiana sotto forma di predicato e
argomento, ci accorgiamo che il predicato "essere nero" si
può applicare non solo ai gatti, ma anche a tante altre cose, come
i vestiti, l'inchiostro, i capelli. Possiamo dunque generalizzare la
forma (a) scrivendo in questo modo:
(b) essere nero (x)
D'altra parte la forma di questo predicato non vale
solo per la proprietà "essere nero": anche la proprietà
"essere affamato" ha la medesima forma. Possiamo dunque
generalizzare la forma del predicato riscrivendo (b) come:
(c) p (x)
La formula (c) esprima la forma generale di tutti i
predicati che si applicano ad un solo argomento. La traduzione delle
espressioni del linguaggio naturale in formule di un linguaggio
formale potrebbe proseguire prendendo in considerazione asserzioni
come "il gatto mangia il topo". In questo caso l'enunciato
esprime una relazione tra due oggetti: la relazione
"mangiare" che un soggetto (il gatto) ha con un oggetto
(il topo). Siamo dunque in presenza di un predicato a due argomenti:
(d) mangiare ( gatto , topo )
Anche per questi predicati valgono le considerazioni
sulla generalizzazione fatte sopra. Naturalmente la formalizzazione
dei singoli enunciati non è sufficiente per dare una forma logica
al linguaggio. Occorre anche formalizzare quelle parole che servono
a collegare tra loro enunciati semplici per formarne di complessi
come "il gatto è nero e mangia il topo". Nel linguaggio
comune queste tipo di parole sono conosciute come congiunzioni: 'e',
'oppure', "se … allora". Se ci pensiamo le congiunzioni
possono essere considerate una sorta di operatori che permettono di
connetter enunciati. In logica dunque le particelle del linguaggio
comune sono state trasformate in operatori o connettivi: ovviamente
per fare questo è stato necessario fissare il loro significato. Gli
operatori logici fondamentali sono 'AND', che corrisponde alla
congiunzione 'e'; 'OR', che corrisponde alla congiunzione 'o' quando
viene usata in senso non esclusivo (quando cioè si intende
sostenere o una cosa o l'altra o tutte e due); 'NOT', che cattura il
senso dell'avverbio di negazione 'non'. Alla luce di questo
ulteriore passaggio siamo in grado di dare una traduzione logica
della frase "il gatto è nero e mangia il topo", che
diverrebbe:
(e) essere nero (gatto) AND mangiare ( gatto ,
topo )
Oltre a escogitare un modo per formalizzare la
struttura logica degli enunciati, i logici hanno anche dimostrato
che - una volta accettate certe assunzioni abbastanza naturali sul
funzionamento dei connettivi utilizzati per costruire enunciati
complessi a partire da enunciati più semplici - la verità o
falsità di enunciati complessi può essere valutata in modo
meccanico a partire dalla verità o falsità degli enunciati che li
compongono.
La formalizzazione logica, unita a un dizionario di
termini che dia significato ai predicati e agli argomenti degli
enunciati semplici, dunque, può essere usata per analizzare il
significato e la verità o falsità di frasi del linguaggio
naturale. Per farlo, è però necessario 'riscrivere' queste frasi
attraverso la corrispondente forma logica. I modi in cui questa
operazione viene fatta sono molti, e non possiamo soffermarci su di
essi. In generale possiamo dire che il procedimento si articola in
varie fasi: la prima consiste nel fare l'analisi grammaticale di una
frase e nel riportarla alla sua forma standard. Questa forma
standard poi viene tradotta in forma di predicati e argomenti.
Infine i vari predicati e argomenti vengono ridotti in componenti di
base, facendo ricorso a una specie di dizionario, in modo tale da
rispettare la forma logica. La riduzione in componenti verifica
anche che l'associazione di un argomento non infranga dei vincoli,
espressi anche essi in forma logica. Essi ad esempio specificano che
i possibili soggetti di "mangiare" sono esseri animati: un
tavolo non può mangiare alcunché! I micromondi e SHRDLU
La rappresentazione del significato basata sulla
analisi logica delle frasi e sulla scomposizione in componenti dei
termini lessicali, che pure comporta delle notevoli difficoltà, si
è dimostrata ben presto insufficiente al fine di dotare i computer
della capacità di comprendere veramente il significato del
linguaggio. I problemi di questo modo di procedere sono molteplici.
In primo luogo, come scegliere i componenti minimi del significato
dei termini? Su questo aspetto le proposte sono state molteplici, ma
nessuna si è rivelata soddisfacente.
Ma il problema più rilevante è un'altro. Prendiamo
ad esempio la frase
(a) Fabio era stato invitato al compleanno di Ugo,
ma quando agitò il suo salvadanaio non sentì nessun rumore
Per capire il senso di (a), che ogni parlante
italiano è in grado di interpretare senza troppi sforzi, non basta
conoscere il significato delle singole parole e ricostruire la sua
forma logica (ammesso che sia possibile). Infatti essa sottintende
una mole notevole di informazioni che non sono espresse
esplicitamente dalle singole parole. Ad esempio, occorre sapere che
di norma quando si è invitati ad una festa di compleanno si porta
un regalo al festeggiato; che per comperare regali occorre del
denaro; che alcune persone tengono i loro risparmi nei salvadanai; e
che il denaro dentro il salvadanaio, in genere, fa rumore se viene
scosso. Insomma, per capire il linguaggio dobbiamo anche essere in
grado di collocare le frasi in un contesto di riferimento, dal quale
possiamo estrapolare tutte le informazioni implicite nella frase.
Generalizzando, potremmo dire che un agente
intelligente (naturale o artificiale che sia) deve possedere una
dettagliata conoscenza del mondo nel quale vive per essere in grado
di parlare, ragionare e, a maggior ragione, agire su di esso. A
questo punto si pongono due questioni: quanto dettagliata deve
essere tale conoscenza? E in che modo possiamo rappresentarla in
forma simbolica?
Intorno al 1970 una serie di ricercatori pensò che
per rispondere a queste domande la strada migliore fosse quella di
circoscrivere e semplificare il problema generale costruendo dei
programmi che avessero una conoscenza perfetta di mondi molto
piccoli e semplici, o micromondi: "Un micromondo è un dominio
artificiale limitato, i cui possibili oggetti, le possibili
proprietà e i possibili eventi sono definiti in anticipo in modo
ristretto ed esplicito. Gli scacchi, per esempio, sono un micromondo:
ci sono solo un numero limitato di pezzi e mosse lecite, e tutto è
chiaramente definito dalle regole. A differenza di un vero
condottiero medievale, uno stratega degli scacchi non deve mai
preoccuparsi di epidemie, scomuniche, malcontento fra le file dei
suoi guerrieri o della comparsa di cosacchi all'orizzonte: perché
nulla può accadere in un micromondo che non sia permesso
espressamente nella sua definizione."
L'idea era quella di eliminare il problema del
livello di dettaglio delle conoscenze (il mondo reale è veramente
complicato, e le conoscenze che perfino un bambino di soli quattro o
cinque anni possiede sono sterminate) per concentrarsi sul modo in
cui tali conoscenze sono rappresentate e utilizzate. In un secondo
momento si sarebbe passati ad estendere la conoscenza per renderla
abbastanza vasta e complessa da dare conto del mondo reale.
Il più famoso tra i programmi che abitavano nei
micromondi è SHRDLU realizzato da Terry Winograd all'inizio degli
anni 70. Il mondo di SHRDLU è noto come mondo dei blocchi: si
trattava di un ambiente costituito da una tavola su cui erano
appoggiati una serie di blocchi, piramidi e scatole colorati.
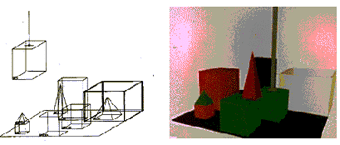
Figura 2 - Due raffigurazioni del mondo dei
blocchi di SHRDLU
Naturalmente la conoscenza che il programma aveva di
questo mondo era puramente simbolica: insomma il mondo di SHRDLU era
un ambiente virtuale. Tuttavia per il programma esso era un mondo a
tutti gli effetti, tanto che SHRDLU era in grado non solo di parlare
correntemente in inglese su di esso, ma anche di agire mediante un
braccio virtuale. In sostanza SHRDLU avrebbe potuto senza problemi
controllare un robot che manipolava elementi reali su un tavolo .
Grazie alla sua profonda 'conoscenza del mondo'
SHRDLU era in grado sostenere lunghe conversazioni in inglese,
eseguire i compiti che gli venivano indicati (naturalmente in modo
virtuale) e perfino motivare le sue azioni. Quello che segue è un
breve estratto da una delle sue conversazioni, a cui abbiamo
aggiunto una traduzione in italiano:
Persona: how many things are on top of green
cubes? [quante cose ci sono sopra i cubi verdi?]
SHRDLU: i'm not sure what you mean by "on top of
"in the phrase "on top of green cubes" . Do you mean:
1 - directly on the surface 2 - anwhere on top of? [non sono sicuro
su cosa intendi con 'sopra' nell'espressione 'sopra i cubi verdi'.
Intendi 1- direttamente sulla superficie 2- ovunque sopra ai cubi?]
Persona: 2
SHRDLU: three of them [ci sono tre cose]
Persona: had you touched any pyramid before you put the green
one on the little cube? [avevi toccato qualche piramide prima di
mettere quella verde sul cubo piccolo?]
SHRDLU: yes, the green one [si quella verde]
Persona: when did you pick it up? [quando l'hai presa?]
SHRDLU: while i was stacking up the red cube, a large red
block and a large green cube [mentre stavo mettendo l'uno sopra
l'altro il cubo rosso, un blocco rosso grande e un cubo verde
grande]
Persona: why? [perché?]
SHRDLU: to get rid of it [per toglierlo di mezzo]
Persona: why did you do that? [perché l'hai fatto?]
SHRDLU: to clean off the red cube [per liberare il cubo
rosso]
Persona: why did you clear off that cube? [perché hai
liberato il cubo rosso]
SHRDLU: to put it on a large green cube [per metterlo su un
cubo verde grande]
Persona: why did you do that? [perché l'hai fatto?]
SHRDLU: to stack up the red cube, a large red block and a
large green cube [per mettere uno sopra l'altro il cubo rosso, un
blocco rosso grande e un cubo verde grande]
Persona: why did you do that? [perché l'hai fatto?]
SHRDLU: because you asked me to [perché me lo hai chiesto]
Come potete vedere SHRDLU è in grado di considerare
retrospettivamente ciò che ha fatto, e riesce anche a trovare delle
motivazioni per quelle azioni che non gli sono state richieste
esplicitamente ma che ha dovuto eseguire al fine di obbedire ad un
comando. In altre conversazioni il programma mostra anche la
capacità di imparare il significato di parole nuove che non sono
presenti nel suo vocabolario, posto che esse vengano definite dal
suo interlocutore mediante termini conosciuti.
Un programma come SHRDLU costituisce senza dubbio un
notevole passo in avanti rispetto ad Eliza o Parry. Tuttavia non si
può in alcun modo dire né che SHRDLU capisca veramente ciò che
dice, né che la sua organizzazione interna sia in qualche modo una
plausibile spiegazione del comportamento intelligente umano. Ad
esempio SHRDLU ricorda tutto ciò che accade nel suo mondo, mentre
è evidente che un essere umano seleziona le cose da immagazzinare
in memoria in base a ciò che ritiene importante. Il fatto è che il
mondo dei blocchi è troppo povero e soprattutto è del tutto
prevedibile. SHRDLU non si deve aspettare sorprese, mentre qualsiasi
creatura vivente (più o meno intelligente) ha un controllo limitato
sul suo ambiente. E con tutta probabilità è proprio la necessità
di migliorare la capacità di prevedere il comportamento di un
ambiente ostile che ha determinato nel corso dei millenni
l'emergenza di comportamenti intelligenti nella nostra specie. La rappresentazione della conoscenza
Gli evidenti limiti di SHRDLU (e di altri suoi
simili) resero ben presto evidente che la scorciatoia dei micromondi
era un vicolo cieco. Se veramente si intendeva sviluppare programmi
intelligenti, era necessario affrontare in modo diretto il problema
di fornire alle macchine digitali una conoscenza esaustiva del mondo
reale, e possibilmente anche una conoscenza di se stesse.
Proprio su questi temi, a partire dagli anni 70, si
è concentrata l'attenzione di moltissimi ricercatori e studiosi di
intelligenza artificiale. Ne sono derivati una grande mole di teorie
relative al modo in cui la nostra mente rappresenta e organizza le
informazioni sul mondo, e una altrettanto grande (se non più
grande) quantità di formalismi e linguaggi specializzati nella
rappresentazione della conoscenza (knowledge representation).
Le reti semantiche
Uno dei formalismi per la rappresentazione delle conoscenze più
diffusi nella IA sono le cosiddette reti semantiche. La prima
formulazione del concetto di rete semantica si deve a Ross Quillian,
che lo elaborò nel 1968 per costruire un modello
dell'organizzazione dei significati delle parole nella memoria e
della capacità di associare concetti. Successivamente molti altri
studiosi hanno proposto evoluzioni e potenziamenti del modello
originale, senza però distaccarsi delle primitive intuizioni di
Quillian.
Ma che cosa è una rete semantica? Secondo Quillian
i concetti (o significati delle parole, che per quanto ci concerne
possono essere considerati la stessa cosa) nella nostra mente sono
organizzati in una struttura reticolare. Solo che in questa rete
esistono due tipi di nodi: i nodi tipo e i nodi occorrenza. I nodi
tipo corrispondono ai significati delle singole parole. Da ogni nodo
tipo si dipartono una serie di collegamenti o archi che terminano
nei nodi occorrenza. Questi ultimi hanno la funzione di descrivere
il significato della parola in questione. Tale descrizione, come
avviene nei dizionari, si basa sull'uso di altre parole che sono il
contenuto dei nodi occorrenza. A sua volta ciascun nodo occorrenza
è collegato mediante un arco al nodo tipo che ne specifica il
significato. Insomma nella rete ogni parola deriva il suo
significato da un certo numero di altre parole.
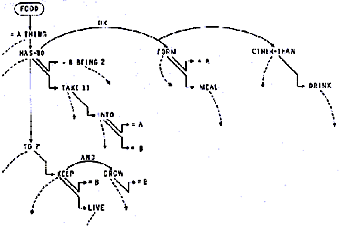
Figura 3 - La rete semantica di Quillian per la
parola 'food'
Inoltre gli archi che collegano i nodi specificano
diversi tipi di relazione: ci sono archi che indicano relazioni di
sottoclasse, o di appartenenza ad un genere: ad esempio l'arco che
da "cibo" porta a "cosa". Gli archi di questo
tipo sono successivamente divenuti noti come archi 'IS A', ovvero
archi 'è un(a)…'. Vi sono poi archi che indicano una relazione di
congiunzione tra due componenti del significato di una parola. Archi
che invece indicano una disgiunzione tra più significati e così
via.
Appoggiandosi ad una rete semantica (opportunamente
tradotta in un linguaggio informatico) un programma è in grado non
solo di risolvere il significato delle espressioni lessicali, ma
anche rispondere a domande come: "è vero che il cibo è una
cosa che si mangia?". Infatti nella rete della figura esiste un
percorso che permette di dedurre proprio questa conclusione.
I frame di Minsky
Le reti semantiche come quelle cui abbiamo accennato nel paragrafo
precedente hanno due limiti. In primo luogo ogni singolo concetto è
considerato come un elemento unitario. Sebbene gli archi che
collegano un nodo ad un altro possano essere considerati una
rappresentazione articolata del significato di un termine, questa
articolazione sembra comunque troppo limitata per rendere conto di
tutte le varie componenti di un concetto. In secondo luogo la
specificazione del significato di un concetto è estremamente
rigida: ogni concetto infatti viene descritto mediante una serie di
componenti obbligatori, un po' come avviene nelle definizioni di un
dizionario.
Questo modo di rappresentare la conoscenza è
inadeguato per rendere conto del modo assai rapido in cui un essere
umano è in grado di accedere alle conoscenze immagazzinate nella
sua memoria e di utilizzarle per ragionare, comprendere un discorso
in lingua naturale o riconoscere gli oggetti e le situazioni che gli
si presentano. Per capire che cosa intendiamo dire, prendiamo in
considerazione la seguente frase:
(a) Fabio entrò in cucina e si mise a sedere
Ognuno di noi è in grado capire perfettamente il
suo significato. A nessuno verrebbe in mente di chiedere con aria
stupefatta "si mise a sedere dove?". Tuttavia se
analizzassimo il significato stretto di ogni singola parola della
frase, non troveremmo da nessuna parte il concetto di
"sedia". Questo significa che nella nostra memoria il
concetto di cucina deve avare una struttura assai più ricca di
quanto non preveda un dizionario, e che questa struttura deve
comprendere tra le altre cose una sorta di descrizione di una cucina
standard in cui si dica (o si mostri) che in una cucina si trovano
di norma una tavolo e delle sedie.
D'altra parte, se qualcuno ci dicesse:
(b) Fabio era stanchissimo ma quando entrò in
cucina
non trovò nulla su cui sedere
non troveremmo nulla da obiettare. Evidentemente il
fatto che il concetto di cucina preveda che in una cucina ci siano
di norma un tavolo e delle sedie non deve essere vincolante ai fini
della comprensione. Siamo disposti a concedere che in una cucina
sedie e tavoli possano anche mancare. Un fenomeno simile avviene
quando ascoltiamo una frase come
(d) "Lo struzzo è un uccello che non può
volare".
La proprietà di essere un "essere animato che
vola" sembra essere parte integrante del concetto di uccello.
Ma il fatto che (d) non sia giudicata una contraddizione (sebbene ci
stupisca) mostra chiaramente che la struttura del concetto di
uccello deve essere piuttosto flessibile, fino al punto da concedere
che possa esistere un uccello che non può volare.
Per rendere conto di queste caratteristiche della
nostra memoria concettuale, e per riprodurla su un computer, Marvin
Minsky, uno dei pionieri dell'intelligenza artificiale, ha elaborato
la nozione di frame (che in inglese significa struttura o cornice).
Si tratta di una nozione molto simile a quella di stereotipo. Un
frame infatti è una struttura che raccoglie e organizza secondo
vari livelli di obbligatorietà tutte le informazioni che sembrano
comporre un determinato concetto. Alcune informazioni sono
considerate necessarie, altre probabili e altre solo opzionali. Ad
esempio il frame per il concetto di cucina potrebbe avere questa
struttura:
|
Cucina
Sottoclasse di: stanza
Funzioni (sempre): preparare cibo
Funzioni (probabile): consumare cibo
Ha come costituenti (sempre): pareti, soffitto, pavimento
Contiene (sempre): macchina a gas o elettrica oppure camino
Posizione (quasi sempre): a ridosso di parete
Contiene (quasi sempre): frigorifero, lavandino
Posizione (quasi sempre): a ridosso di parete
Contiene (probabilmente): tavolo
Posizione (probabile): centro stanza oppure a ridosso di parete
Contiene (probabilmente): sedie
Posizione (probabile): intorno a tavolo
Etc. |
In realtà questo è un abbozzo estremamente
grossolano di quello che dovrebbe essere un vero frame, che dovrebbe
avere un numero assai maggiori di informazioni e che soprattutto
dovrebbe specificare in modo molto più rigoroso proprietà e
relazioni per essere utilizzato da un computer (e da un cervello, se
esso lavora in modo non troppo dissimile da un computer). Comunque,
ci permette di capire quale dovrebbe essere la sua struttura.
In primo luogo vediamo che le componenti del frame
sono articolate in varie tipologie, che corrispondono alle diverse
proprietà dell'oggetto reale cucina. In secondo luogo, possiamo
notare come alcune componenti della rappresentazione siano
qualificate come obbligatorie, altre come probabili e altre ancora
come opzionali. Tutte le componenti non obbligatorie sono presenti
nel frame per default: sono cioè considerate parte del prototipo di
cucina fina a prova contraria.
Quando leggiamo in un testo o ascoltiamo in un
discorso la parola "cucina", il frame viene richiamato
dalla memoria nella sua forma standard. Se tuttavia procedendo nella
lettura o nell'ascolto si riceve l'informazione che nella tale
cucina non sono presenti sedie, allora la componente relativa viene
cancellata. Questo non produce alcuna contraddizione, poiché il
fatto di contenere sedie era una informazione per default e dunque
rinegoziabile. Viceversa se si apprende che nella presunta cucina
non vi sono né una macchina a gas né un camino, ma un letto, un
comodino e un armadio, il frame cucina risulterebbe in
contraddizione con le nuove informazioni e dunque concluderemmo che
quella stanza non era una cucina ma una stanza da letto.
Un ultimo aspetto importante dei frame su cui vale
pena soffermare l'attenzione è che essi sono interconnessi tra loro
in un modo molto ricco e articolato. Infatti, ogni componente di
ciascun frame è collegato al frame che ne descrive la struttura: il
componente 'sedia' del frame 'cucina' dunque è collegato con il
frame 'sedia', così come il componente 'stanza' è collegato con il
frame 'stanza'. I frame insomma costituiscono una rete di concetti .
I collegamenti tra frame non sono casuali ma organizzano lo spazio
concettuale in base a precise relazioni: alcune di esse sono più
marcate (ad esempio le relazioni gerarchiche con i concetti iponimi
e iperonimi), altre meno (ad esempio le relazioni associative o
analogiche). In questo modo i frame possono essere usati per
condurre sia i classici ragionamenti di tipo deduttivo, sia forme di
ragionamento più complesse come l'induzione o l'analogia.
Gli script di Schank
Una nozione (e un formalismo) simile a quella di frame è la nozione
di script o copione, elaborata da Roger Schank (un'altro eminente
studioso nel campo dell'intelligenza artificiale) e dal suo
collaboratore Abelson. Come il nome scelto per queste strutture
lascia immaginare, a differenza dei frame (in cui si rappresentano
oggetti o stati di cose), gli script servono a rappresentare eventi
o sequenze di eventi tipici, come 'andare al ristorante', 'andare
dal dottore' e così via.
Essi infatti furono sviluppati da Schank per
consentire ad un programma di comprendere o parafrasare delle storie
o delle brevi narrazioni. Prendiamo ad esempio la seguente
storiella:
(a) Fabio andò in un ristorante. Ordinò alla
cameriera
una bistecca ai ferri. Pagò il conto e se ne andò.
Ora, se dopo aver letto questa storia, qualcuno ci
chiedesse "che cosa ha mangiato Fabio?" senza alcuno
sforzo risponderemmo "una bistecca ai ferri". Tuttavia
nessuna delle frasi che compone (a) dice esplicitamente che Fabio ha
effettivamente mangiato la bistecca. Evidentemente la nostra
risposta è stata inferita da un insieme di conoscenze di contesto
che ci dicono che di norma quando si va al ristorante e si ordina
qualcosa poi lo si mangia. Ebbene, secondo Schank queste conoscenze
di contesto sono organizzate proprio sotto forma di script: "…
uno script è un insieme di scanalature pronte a ricevere certi
eventi e non altri. Lo script usato per comprendere qualcosa ci
aiuta a sapere che cosa aspettarci. Uno script dice che cosa
probabilmente seguirà in una catena di eventi stereotipati. Non
solo, ci permette di capire la rilevanza di ciò che di fatto
succede subito dopo: garantisce il collegamento fra gli eventi."
Come vediamo la nozione di script rassomiglia molto
a quella di frame, con la differenza che pone l'enfasi sul
succedersi di eventi piuttosto che sulle proprietà di oggetti. Uno
script infatti è costituito da una serie di scene, che specificano
con estremo dettaglio la sequenza (o la concorrenza ) di eventi che
sono pertinenti per ogni scena. Inoltre lo script specifica anche i
luoghi, i tempi, i personaggi e gli oggetti previsti dalla storia e
indica le condizioni (o motivazioni) di inizio e i risultati finali
(ovvero gli obiettivi conseguiti) della storia. Alcuni script
possono essere divisi in diversi 'sotto-script' (denominati da
Schank 'binari') che si adattano a diverse possibili versioni della
stessa storia. Ad esempio il frame 'ristorante' si articola in
diversi binari in base al tipo di ristorante: c'è così un binario
'fast food', uno 'trattoria rustica', uno 'ristorante di lusso' e
così via. Questo è un esempio estremamente semplificato di una
parte dello script 'ristorante' :
Script: Ristorante
Binario: Trattoria
Oggetti: Tavoli
Menu
Cibo
Conto
Denaro
Personaggi: Cliente
Cameriera
Cuoco
Condizioni di entrata: Il cliente ha fame
Il cliente ha denaro
Risultati: Il cliente ha meno denaro
Il proprietario ha più denaro
Il cliente non ha fame
Il cliente è soddisfatto |
Scena 1: Ingresso
Entrare nel ristorante
Guardare i tavoli
Decidere dove sedersi
Andare al tavolo
Mettersi a sedere |
| Scena 2: Ordinazione |
|
(menu sul tavolo)
Prendere il menu
|
(la cameriera porta il menu)
|
(chiedere il menu)
Chiamare la cameriera
La cameriera arriva al tavolo
Chiedere il menu
La cameriera dà il
menu
|
|
Leggere il menu
Decidere (il cibo scelto)
Chiamare la cameriera
La cameriera arriva
Dire alla cameriera "Voglio (il cibo scelto)" |
Nella seconda scena possiamo notare come in alcuni
casi possano darsi diverse possibilità, che implicano a loro volta
diverse sequenze di eventi. Naturalmente uno script per essere
utilizzato da un programma andrebbe scritto mediante un opportuno
linguaggio, e soprattutto dovrebbe essere assai più dettagliato di
quanto non sia il nostro esempio. Uno dei programmi basati sul
formalismo degli script è SAM (Script Applier Mechanism),
sviluppato dallo stesso Schank e da un gruppo di suoi collaboratori.
Esso era in grado di leggere dei brevi racconti, compresi resoconti
giornalistici, e di farne un sommario in inglese e in spagnolo.
Inoltre poteva rispondere in modo incredibilmente sensato a domande
relative ai fatti narrati nelle storie.
Successivamente al lavoro sugli script, Schank ha
elaborato un'altra serie di formalismi il cui fine era di consentire
ad un programma di individuare il tema di una storia anche senza
possedere nessuna sceneggiatura predefinita. Questi formalismi si
basano sulle nozioni di piano e di scopo e sono state applicate
nella creazione di PAM (Plan Applier Mechanism). Questo programma,
analizzando le frasi di un racconto qualsiasi, era in grado di
individuare le motivazioni dei vari personaggi e di prefigurare i
possibili piani di azione che tali personaggi potevano cercare di
metter in atto per raggiungere i loro obiettivi. Anche PAM si è
dimostrato sorprendentemente efficiente ed ha rappresentato il
modello di riferimento per numerosi programmi di IA sviluppati nel
corso del passato decennio.
|


